Data Partitioning in Distributed Systems
· ☕ 9 min read
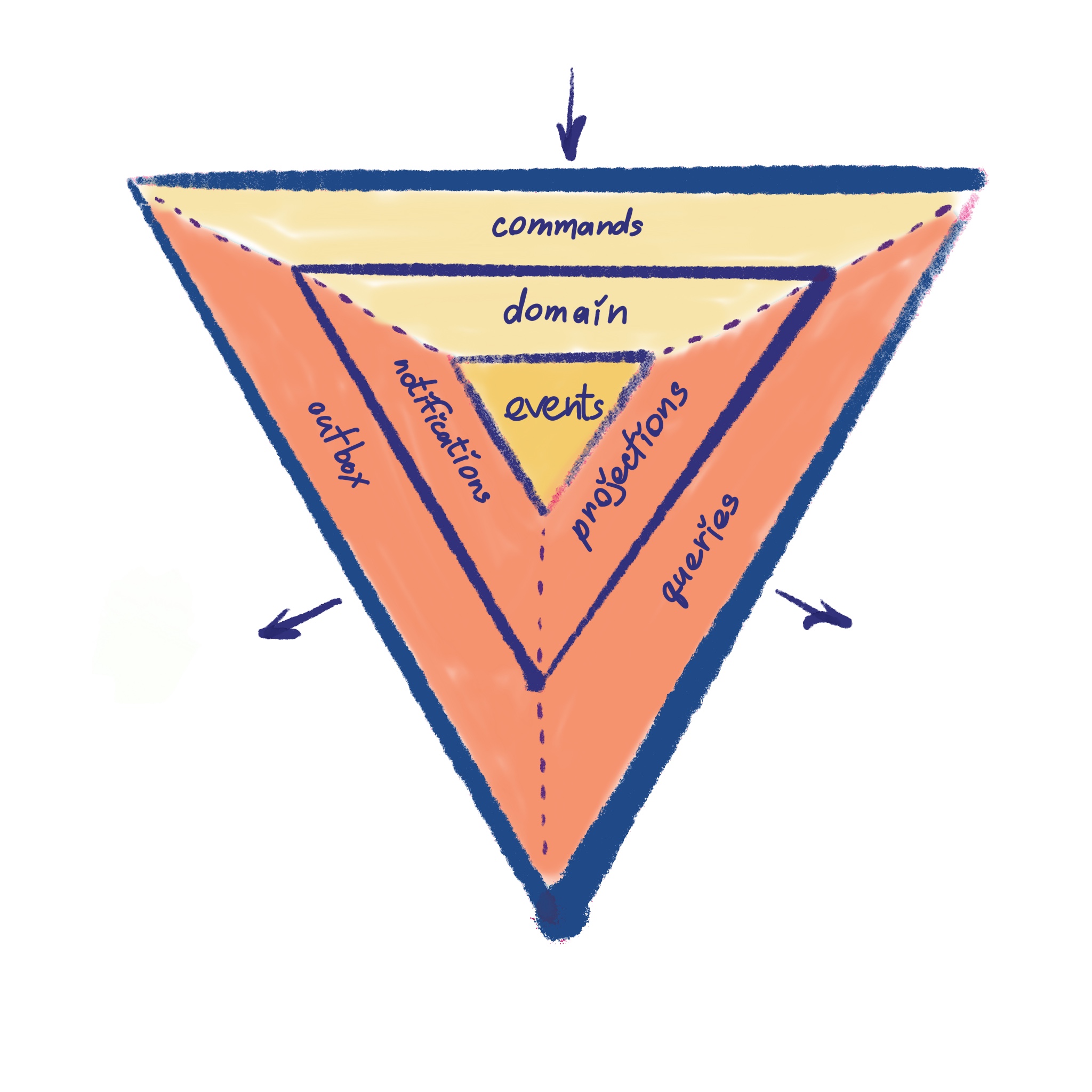
I feel like data storage scalability in distributed or not systems is often overlooked. Whenever we talk about scalability, we usually imply processing scalability in distributed systems. We talk about ways to scale out dedicated service clusters without downtimes or data flow interruptions. I’ve written a few articles about it myself. But today, let’s talk about data scalability. How can we efficiently handle massive data sets without downtime or performance implications?