
Not by coincidence Git has become a default version control system for many of us. Git has proven itself to be predictable and reliable. Especially when it comes to conflict management, history traversal, and other daily developer routines.
I have collected some recommendations that will enhance your day-to-day experience of working with Git. And hopefully, reveal some hidden features that have been laying around all this time.
This article is not an ultimate Git guide by any means. Rather it is a set of common sense practices for using Git effectively.
Branching
Strategy
There are ultimately two main branching strategies feature branches and trunk-based development. Everything else is just a variation of one or another. The biggest distinguishable difference between them is a scope of change that gets merged into the trunk branch (aka master, main, core, mainline).
Feature Branching is a poor man’s modular architecture, instead of building systems with the ability to easily swap in and out features at runtime/deploytime they couple themselves to the source control providing this mechanism through manual merging.
— Dan Bodart
Use trunk-based development when possible. I won’t argue about the advantages of CI/CD, at least not in this article. I’ll just say that as the name suggest you can’t have CI/CD without Continuous Integration (CI). And by definition of the CI, you can’t have it without trunk-based development. Hence you can’t have CI/CD without trunk-based development.
— Atlassian Trunk-based development definition
— AWS CI definition
The most reasonable alternative to trunk-based development is Gitflow. Given all the modern tooling for automation of testing, deployment, and releases Gitflow happens to be useful, but rarely. Deployment Hell that will unavoidably follow using Gitflow will likely cross any benefit you may think of.
Trunk-based development
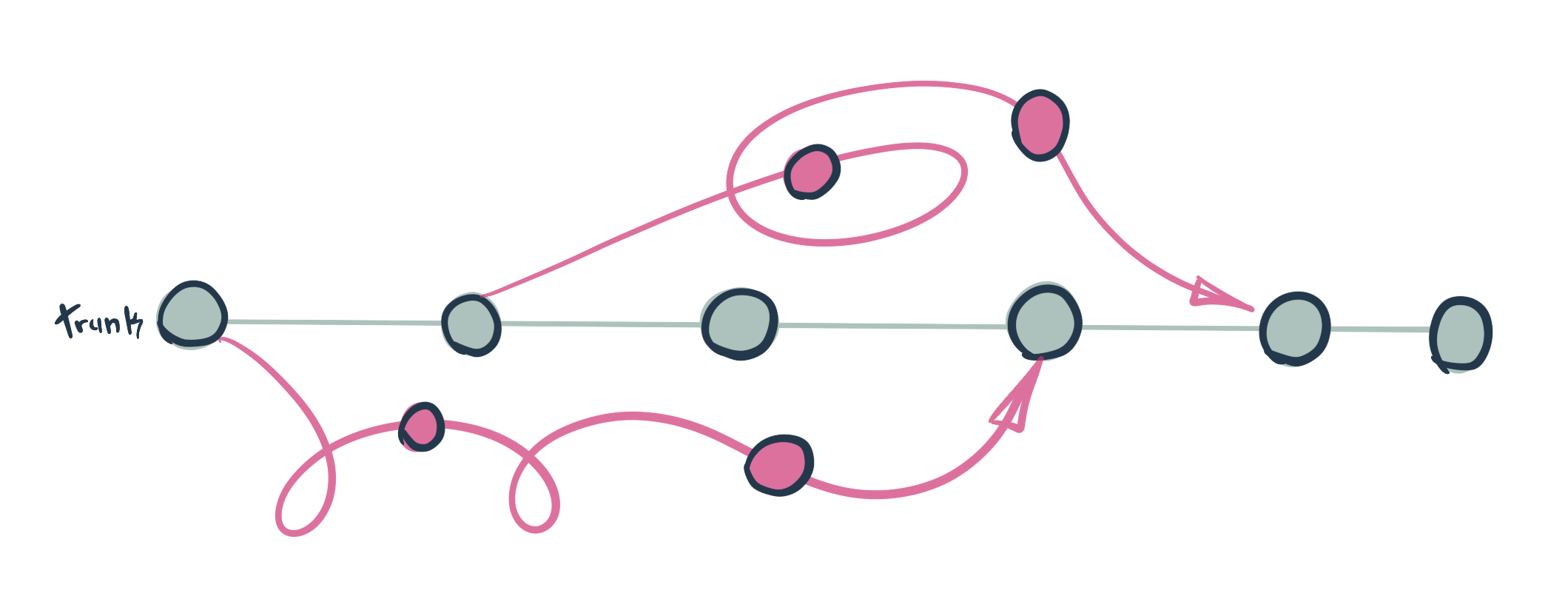
The diagram above was inspired by LeRoy’s illustration
Unfortunately trunk-based development is not always available right away. As the name suggests it is a process. Development process. And it has certain entrance criteria.
-
It should be possible to develop in small batches. It may be not only the developer’s prerogative as the work scope depends on planning. If the work is sliced in small chunks during the team planning then developing in small batches is a no brainer
-
The code review process should be balanced.
-
Avoid overly heavy code-review process. Otherwise, developers will attempt to squeeze in as much work as possible to minimise the number of code reviews they have to go through.
-
Somewhat opposed to the previous point, don’t make it a box-ticking exercise
-
Code review is work and has to be recognised as such. It should be assigned and executed consciously.
-
Code review should be a priority. Active branch lifetime should be minimised. Hence merged asap. So if the code is ready it should be reviewed asap.
-
-
The trunk branch should always stay healthy. Trunk branch health is an integral aspect of team performance. Thus there should be no way to break trunk branch.
-
Reviews, automated tests, and builds should be exhaustive and efficient.
Naming
The most common use case for branch names is when we are looking for a specific branch to checkout. Consequently, the more discoverable branch is, the better.
Usually, we know either the ticket number or the gist of work that has been (or will be) done there. However, we rarely know the exact name. It is often a good idea to incorporate a ticket number together with a distilled summary of the work. E.g. 123654-form-buttons-styling-uplift or fixing-query-parameters-encoding-bug-344400
Clean up
Another pretty obvious one, but often overseen. Once the branch is no longer needed, it must be removed. The lower the number of obsolete branches, the better discoverability of active branches. Nowadays it is very easily automated task
Commits
Message
I like to think about a branch as a story that the developer tells about the work that has been done. Where the branch name is the name of the story. And every commit message is a sentence that builds the story. The frequency of commits and the content of commit messages should make sense in the context of the story you are trying to tell and should somewhat follow one another. Writing a commit message should be an intentional process, not a side-effect of using Git.
Make sure you can commit from your IDE, and memorise the shortcut. Remove all unnecessary commit hooks, especially long-running ones.
Commit should not feel like a burden, it should feel like saving a file.
Size
You should commit often, therefore the size of each commit must be reasonably small. Base your commits around logical units of change. As long as you do that, the commit message will be accurate and obvious. Make sure you don’t get carried away as commit messages must stay concise, remember it is just a sentence in the story, not the story on its own.
Commit History
We have slightly touched base on the commit history before. Depending on the scope and the context we will be perceiving and using commit history differently.
In the context of the WIP branch (e.g. if you are reviewing someone’s work) we are interested in work that has been done in the scope of a given ticket/task/story, hence the more details provided the better.
However, when we are looking at the trunk branch we are looking at the history in the scope of the project as a whole. And hardly there will be much value in a very granular view.
WIP Branch History
Generally ambiguous commit history on this level is a side-effect of poorly planned work. You must know at least in broad strokes how you are planning to tackle the task. As long as the work is reasonably planned using commits to craft a well-written story will be a natural and effortless act.
Take a look at 12332-uplifting-checkout-form branch history
12332-uplifting-checkout-form
- introduced a theme provider
- updated buttons to use the theme provider
- updated text fields to use theme provider
- removed redundant info banner
- fixed confirmation text typo
- addressed review comments
It tells a story, isn’t it? By looking at the branch and commit messages you can see what has happened, if you require more details you can get down to the code level. Try to avoid any code specifics in the commit message, variable names, classes, etc., anything that will be anyway visible on the code level.
Ideally, you should be able to review what has been done by only looking at the commit history, although I would not recommend doing so.
Trunk Branch History
The most often use case for commit history on this level is during the process of figuring out wtf have happened with this code…
git blame ruining friendships since 2005I think this will sound familiar to you… You are working on a ticket and you stumble across a piece of code that you need to use/change/refactor. It works somehow but looks rather confusing and illogical. The code has been there for months or perhaps years. It has been written by someone who left the company ages ago… And yet there you are one on one with it…
Comments explaining how code works are no better than documentation. Both get stale very fast. However, comments not only are rarely updated but often get copied all over the code base, completely losing even remote value.
The biggest advantage of having fluent and articulative history is the ability to time travel and answer the very important question of why? something has been done in a certain way. You can go to “day 1” and see how this whole space ended up where you found it. If you are lucky enough you will find ticket numbers attached to merge commits, so you’ll be able to get even more context.
Merge Strategy
In most cases, I’d suggest using Squash Merge as a trunk branch default merge strategy. Squash Merges will clean the trunk branch history from unnecessary noise that otherwise will leak from WIP branches history. Squash Merges will protect trunk branch integrity and concision. It will keep the history linear, which is much easier to read and rebase on.
When all the work has been done and changes have been reviewed. You are one click away from the merge, it is hard to find a good reason to preserve the WIP branch history anyway.
Merge Conflicts
While you are working on your WIP branch you shouldn’t be overwhelmed with conflicts. If you are, it is typically a consequence of sloppy work planning and mediocre orchestration. The WIP branch lifetime should be short.
However, if you encountered merge conflicts… Rebase. As said before linear history is much easier to read and comprehend. Hence much easier to traverse while traversing the history through the git blame
Bottom line ___
I have tried to distill recommendations and keep them as generic as possible, avoiding any specifics related to the Git VCS provider, automation tools, or company processes. Said that given any specific tool, any of these practices or recommendations can be (and should be) improved significantly.
Hence the final advice: don’t keep your process agnostic to tools, rely on them and use them to the maximum extent.