Data Consistency is an enigma of Distributed Architecture. It is a rather poetic way to say that something is a pain in the ass.
It might not be that obvious at the first glance, but Data Consistency never exists in isolation. It is heavily bonded with Availability and Partition Tolerance. If they sound alien, don’t worry. We will closely look at them and their friendship in a moment
Because of the close bond, the change in one will silently trigger a change in another, and so forth. In its turn, this change train 🚆 will replace one set of problems with another. And there you have it, change on one end, brought problems on the other.
An interdependency between Consistency, Availability and Partition Tolerance in the distributed system has been described by the CAP Theorem. Originally it was formulated by Eric A. Brewer for distributed data stores. But it is applicable for any distributed stateful architecture, hence Microservice Architecture.
I think its applicability is worth explaining.
We will star with Microservice Architecture definition. Here’s a very concise definition
loosely coupled service-oriented architecture with bounded contexts
If we’ll elaborate on it…
A Microservice Architecture is an approach where the application is built with a set of independently deployable services. The separation of concerns (SoC) is used to set service boundaries. Hence each service has its own well-defined purpose. And is either stateless or owns its data.
Me in my previous article
It is not uncommon for a cluster of services to have an interest in the same subset of data. Because each stateful service is supposed to own its data, a cluster like this is a distributed storage for that subset of data. This means we can apply a CAP Theorem to it.
CAP Theorem
The theorem states that, though it’s desirable to have Consistency, Availability, and Partition Tolerance, unfortunately, no system can achieve all three simultaneously.
In other words, we can choose at most two from given three characteristics.
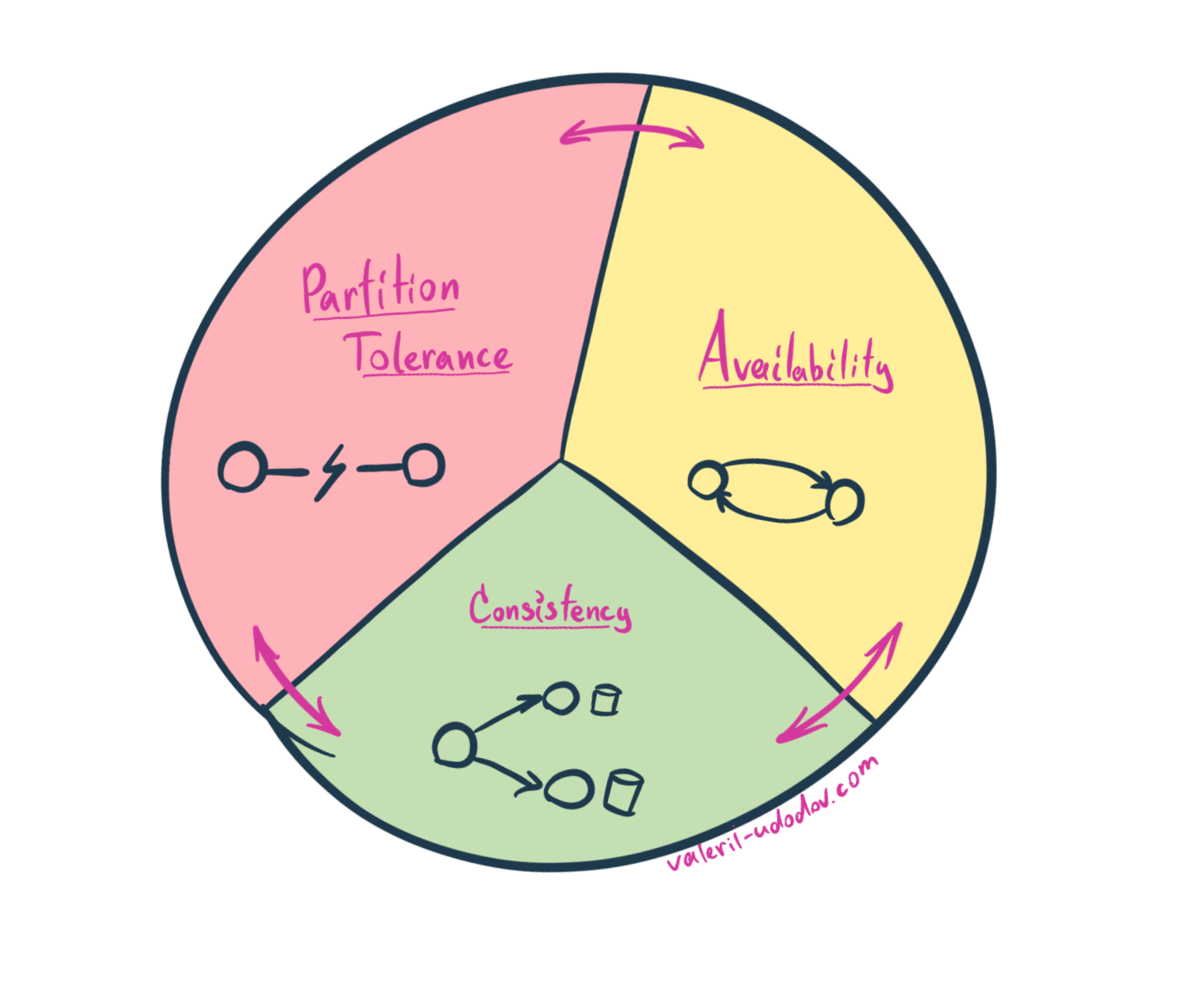
Before refining this theorem for Microservices let’s define C, A, and P…
Consistency
Data Consistency comes in two flavors: Strongly Consistent or Eventually Consistent.
The data is Strongly Consistent if any two arbitrary services in the cluster that share a subset of data have the same version of the data at any given moment.
The data is Eventually Consistent if any two arbitrary services in the cluster share a subset of data but don’t necessarily have the same version of the data at any given moment. But they guaranteed to have the same version eventually.
This theorem implies Strong Consistency by this characteristic. In other words, if your architecture has this characteristic, the data within is strongly consistent.
Availability
Availability means that any arbitrary service is not blocked/locked at any given moment. Note, it is not an “availability” from an uptime perspective (aka High-Availability), but rather from a serving perspective. The service is available for request processing even though it might not have the latest version of the data at any given moment.
Partition Tolerance
In the context of Microservice Architecture, this characteristic is not really an optional one, it is a given one.
Partition is a break or delay in the communication between services. Having partition tolerance means you are confident in the glue between your services and the underlying infrastructure. Given modern infrastructure, cloud providers and most (all?) modern message brokers guarantee “at least once” message delivery. This is a rather given and non-negotiable for Microservice Architecture.
Refined CAP Theorem (CA Theorem)
Said that let’s refine the general definition of CAP Theorem and turn it into a Microservice Architecture edition. Because Partition Tolerance is a given, we will dismiss it from the definition.
In Microservice Architecture, for any given cluster of services, we can guarantee either Strong Consistency or Availability.
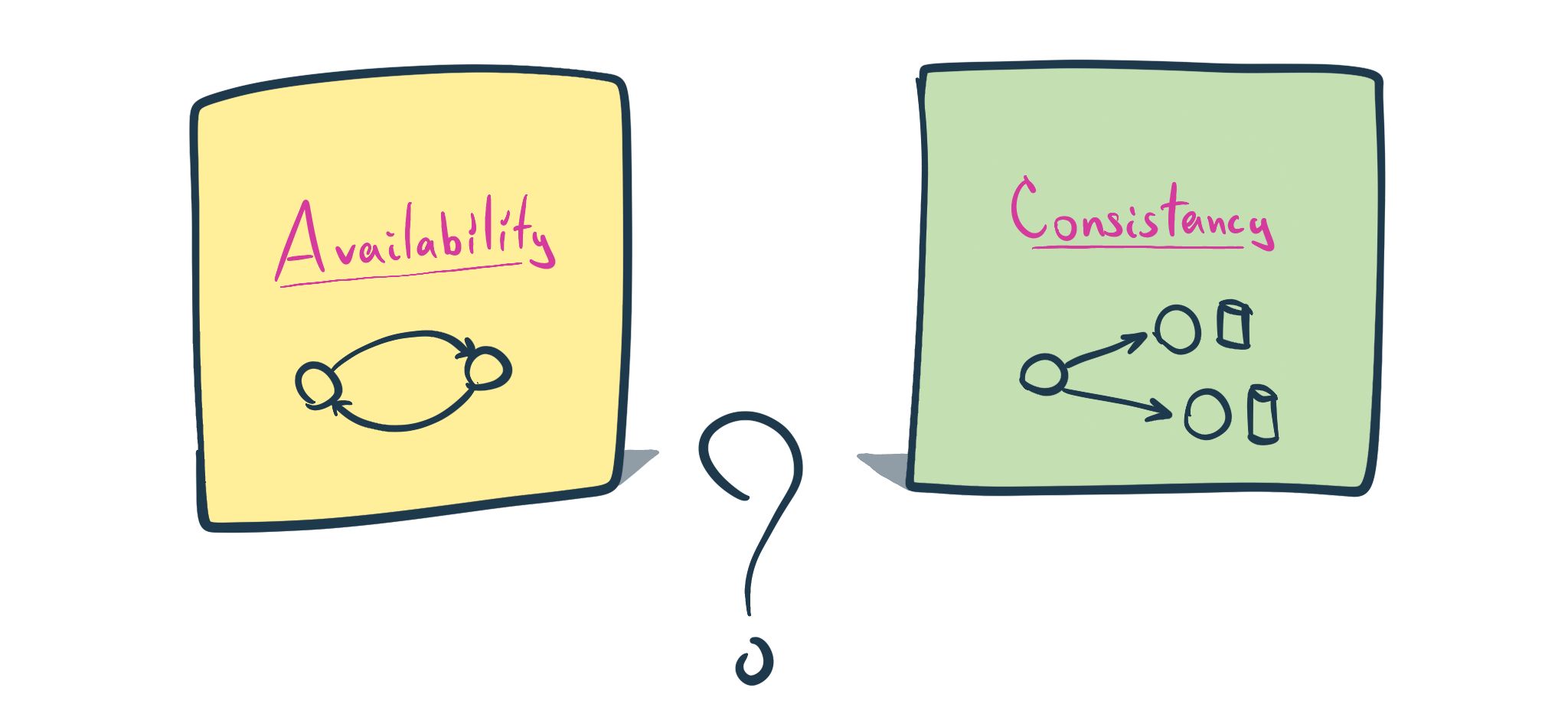
Consistency vs Availability
Let’s look at how we can guarantee one or another characteristic in Microservice Architecture. And at what cost.
Spoiler Alert: as we go, we will observe that for Microservice Architecture the choice is pretty much predefined.
Two-Phase Commit (2PC)
Two Phase Commit (aka Distributed Transaction) is an attempt to commit/write/update a shared piece of information for each service in the cluster in (thanks, captain obvious) two phases. This approach will require a coordinator service that will control the execution of both phases.
- Phase 1: The coordinator checks each service in the cluster on readiness to perform the transaction. This phase locks each service right after service response. The lock is necessary to ensure that when we are going to carry on with the actual operation (phase 2), services will remain in the same state as we leave them in this phase. If any service is not ready, we cancel the whole transaction and unlock all services.
- Phase 2: Actually perform an update operation for each service in the cluster. Once this phase is over, all services are unlocked.
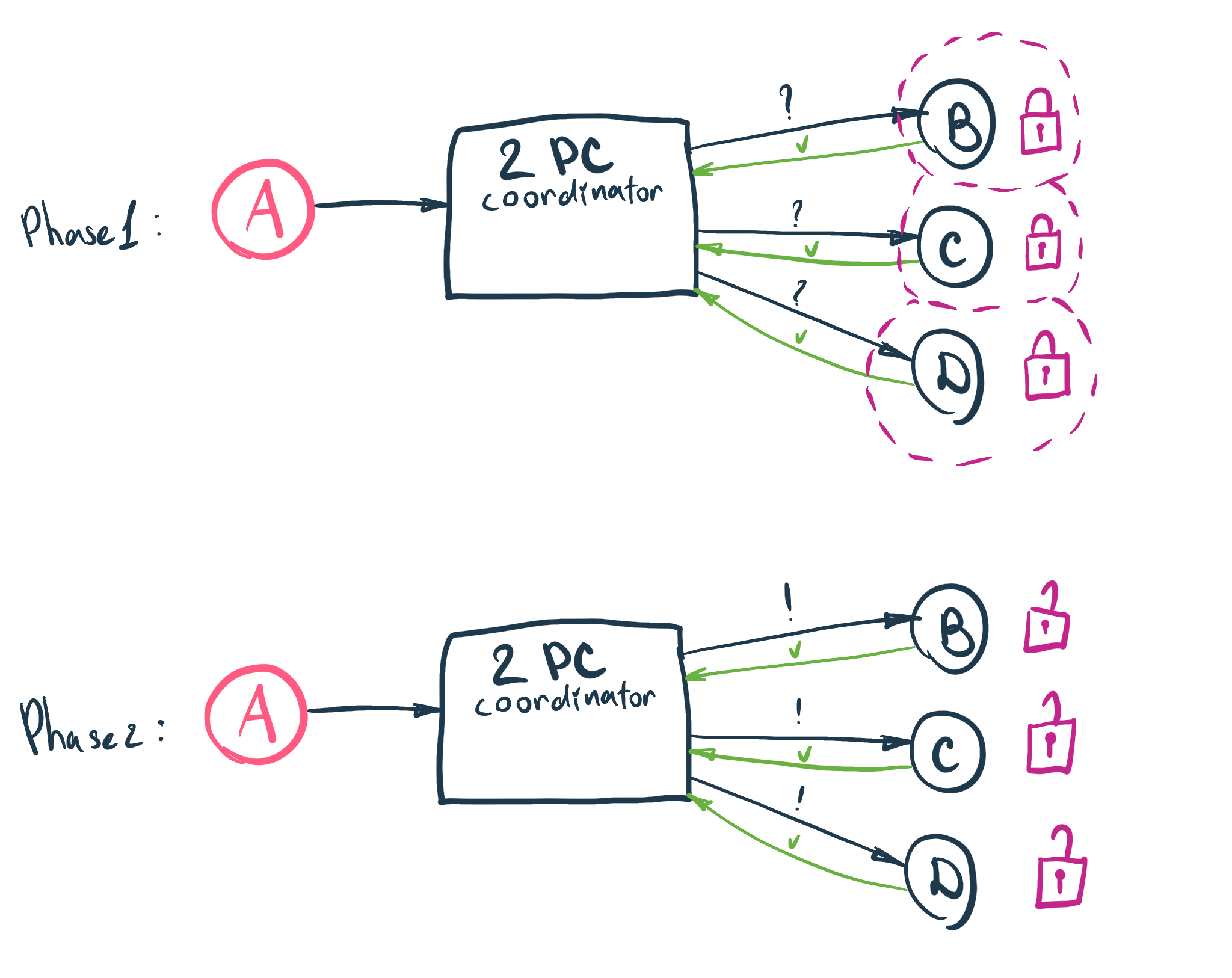
Evidently, this approach guarantees Consistency over Availability (CA Theorem). All services in the cluster will maintain strongly consistent data after every 2PC transaction. However, they will be locked during the whole process, hence unavailable.
If you decide to use this approach in the Microservice Architecture, I’d strongly recommend reconsidering the boundaries of all services included in the cluster. This approach strongly couples all services in the cluster and goes against the definition of Microservice Architecture. And fits well in the definition of the Distributed Monolith.
On top of that, I don’t believe any modern message broker provides 2PC as an option, hence you will have to build and maintain your own Coordinator.
Sagas
In opposition to Two-Phase Commit, Saga guarantees Availability over Consistency. Meaning that data will be eventually consistent.
It is the most common approach to enforcing data consistency in Microservice Architecture.
Saga represents a controlled sequence of independent transactions executed by each service in the cluster. If one of the services fails to execute the necessary transaction, the rollback is performed by a sequence of compensative transactions.
The saga comes in two flavors. Depending on who coordinates its execution. It can be either service choreographed or service orchestrated.
Service Choreography
Service Choreography is a model of decentralized service composition. Knowledge of Saga and how to execute it is spread among services that participate in Saga.
Each service knows which service it needs to send a message to if it successfully executes a local transaction. And it also knows how to construct (and where to send) a compensative message in case a local transaction fails or a successive service sends a compensative transaction.
We wouldn’t necessarily use direct communication between services (like RPC), but rather a queue.
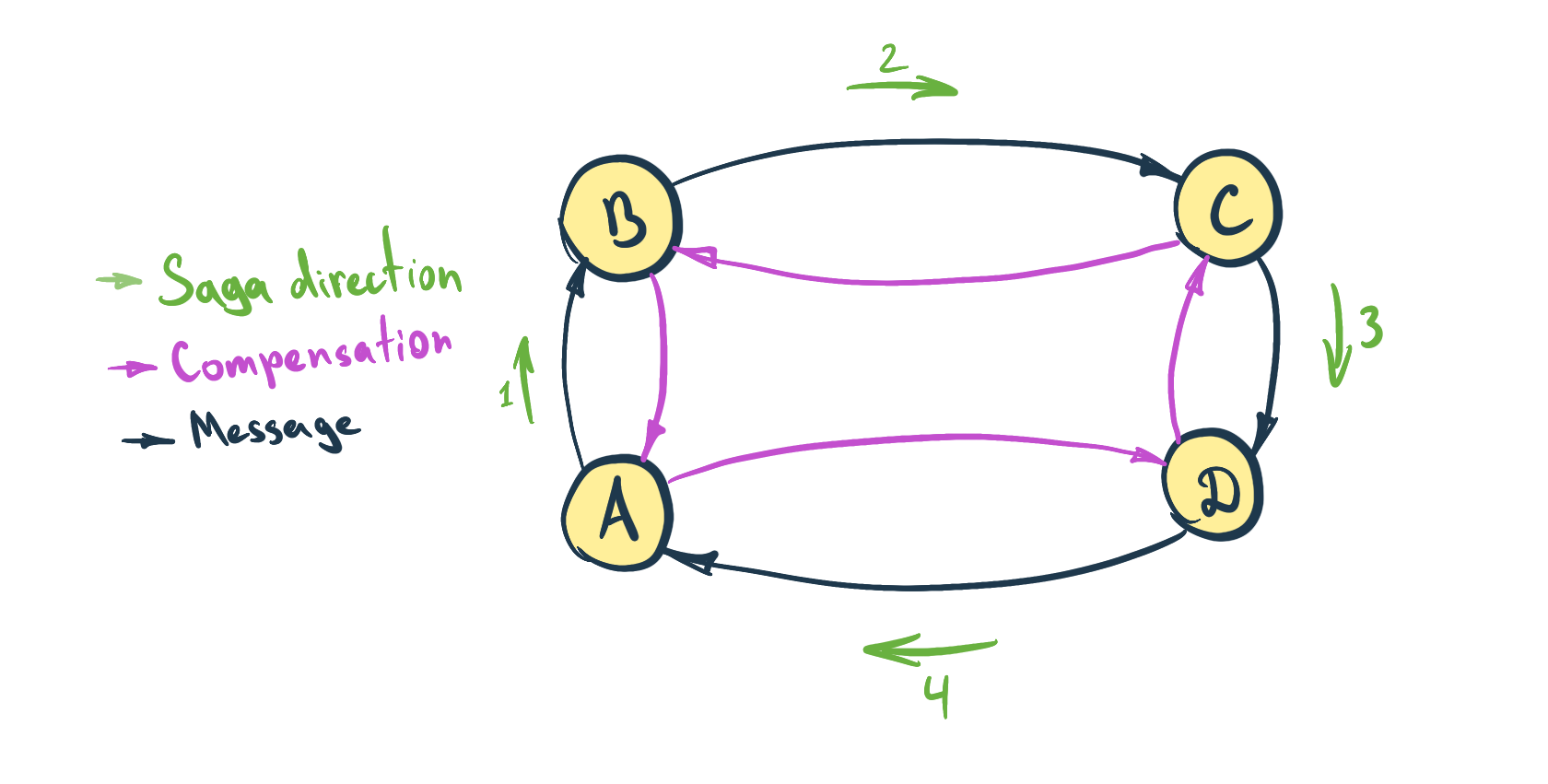
Service Orchestration
Service Orchestration is a model of centralized service composition. Saga is coordinated by orchestration service. The main role of the orchestrator is to deliver the message from the sender to all other Saga participants (aka message subscribers). Often a message broker is employed as an orchestrator. Both general and compensation messages are coordinated by the orchestrator.
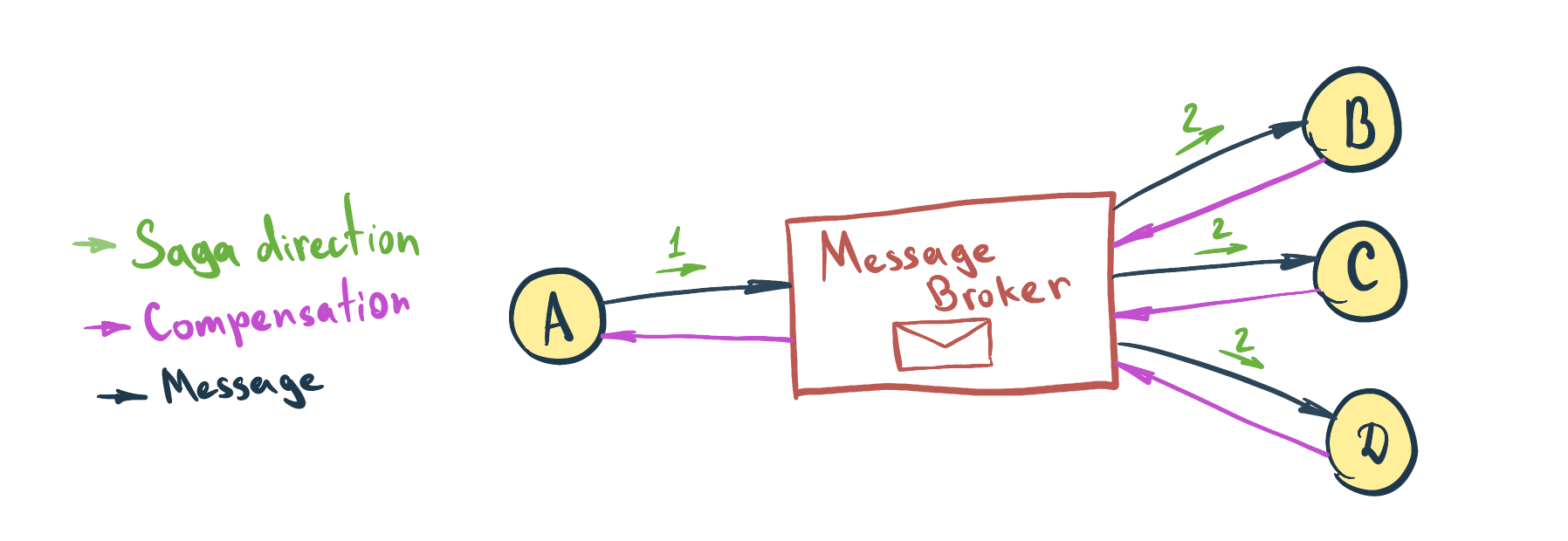
Bottom line
I’d recommend using Service Orchestrated Sagas with a modern Message Broker as an orchestrator for implementing data consistency in the Microservice Architecture.
The message broker will decouple services in the cluster. It will reduce friction surfaces between services, and in opposition to Service Choreographed Sagas, it will remove unnecessary awareness from each service about its Saga predecessor and successor.