This article continues the series dedicated to the CQRS pattern. We will be looking at the Command Query Responsibility Segregation pattern as an architecture, particularly dive into the Querying part and try to find out how to fit it in the HTTP. At the time this article is written, two main protocol versions exist HTTP/1.1 and HTTP/2. Version 3.0 is in the draft, so we are not considering it. The main difference between 1.1 and 2.0 is the transfer layer. The semantics stays the same, hence everything we’ll be talking about here is relevant for both versions.
ℹ️ Don’t forget to check the introductory post to the CQRS pattern, where we’ll go through the idea behind the pattern as well as main actors [CQRS: Inro].
Check all available articles dedicated to applying CQRS architectural patter on top of HTTP [CQRS via HTTP].
If you are looking at CQRS as an option for your current or next project, you are on the right track, make sure to go through another important aspect of CQRS pattern, such as Commanding.
In the first article of the series, I’ve identified the main features of the Query as a part of the CQRS pattern. Take your time and check it out, to get yourself familiar with the CQRS pattern. I’ll quickly highlight main features here:
- A query is a request for some system state. Therefore query must not mutate system state or introduce any side-effects.
- Each query must be a single-purpose query that is tuned to answer only one single question. Queries are bad candidates for applying the DRY principle.
- A query might contain some supportive data for filtering or ordering purposes, but be cautious and not overuse it. The query data suppose to make query reusable for a single view component, not across multiple view components.
- Query response should have only information that was queried, not less, not more. Violation of this point most likely will be a result of violation previous point.
HTTP Request
We will be constructing the HTTP Request for the Query in a similar manner we did for the Command. The first step would be to determine the correct HTTP request method. Picking one of the Nine existing (Eight and a PATCH) methods. As an opposite to the Command, we will be focusing on so-called safe methods. These methods are used for data retrieval and don’t intend any data mutation, this is where the prefix safe is coming from. There are two safe methods available GET and HEAD.

By definition HEAD HTTP Request Method should not return the response body, hence it won’t be able to return the result of the query. Which won’t work for our needs for obvious reasons. The main idea behind the HEAD request is getting HTTP Headers that would be returned with the GET request (e.g. content-length).
However, we might use HEAD request as a pre-query request, to determine if the query result will contain a lot of data and e.g. we need to notify a user about that or fragment a progress bar accordingly to expected payload. It might be useful for improving the user experience. The HEAD request usually implying subsequential GET request, which means query response can be cached in a short-term cache for resolving the successive request.
The response to a GET request is cacheable; a cache MAY use it to satisfy subsequent GET and HEAD requests unless otherwise indicated by the Cache-Control header field
Now that we eliminated the HEAD HTTP Request method, what is left is GET. It seems like this Request Method ticks all our boxes, it safe, idempotent, cachable, have a response body.
The GET method requests transfer of a current selected representation for the target resource. GET is the primary mechanism of information retrieval and the focus of almost all performance optimizations. Hence, when people speak of retrieving some identifiable information via HTTP, they are generally referring to making a GET request.
So GET it is.
Query Name
Similarly to the Command, the Query consists of two data fragments, the name, and the payload. And the only mandatory part -which every query should be supplied with- is the name. Moreover, most likely the majority of times query will contain only the name.
We will follow the path we’ve taken before with the Commanding and treat the Query as an abstract resource. Hence we can legitimately specify a query name in the URI path fragment. The Query to get all potatoes will look like query/get-all-potatoes.
Query Data
The second part of the Query is payload or query data. All the extra data for HTTP GET request supposed to be passed through the URI query parameters. The main disadvantage of URI utilization is a size limitation and its construction on the client-side.
But what about the request body? Its JSON-like structure makes it easier to construct on the client-side and it has less restricted limitations on size.
In initial iterations of the protocol, it was deemed to be a bad tone to use the body with the HTTP GET request message. However, it was changed in further iterations.
A payload within a GET request message has no defined semantics; sending a payload body on a GET request might cause some existing implementations to reject the request.
…
Request message framing is independent of method semantics, even if the method doesn’t define any use for a message body.
That said the body is allowed in the HTTP GET Request message, it is just server not obligated to understand it. However, most of the modern server platforms does it out of the box. It makes sense to keep this part consistent between Commanding and Querying
HTTP Response
After the query was successfully executed we expect query executor to return some data (betweenwhiles no data is acceptable query result, even though this scenario is expected on a rare occurrence). As per 200 OK HTTP Response Code specification (for the GET Request method), the payload (read query result) can be legitimately added to the response. So the full flow of query processing would look as following.
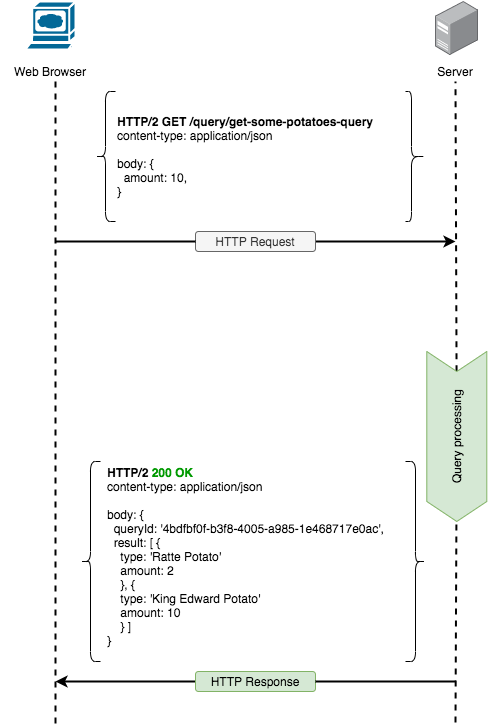
As for failed results we can use appropriate HTTP Response Codes to signal client what exactly went wrong.
Caching
Every time we talk about data retrieval we usually touch caching in one way or another. HTTP provides various ways to cache data. All standard caching practices can be easily adopted with Querying via HTTP.
I will look into two caching strategies I find very helpful. And in conjunction allowing avoid any unnecessary query processing and data transferring.
The first strategy is the In-Memory Caching. It is essentially a Hash Table where a hash function will use a query name and payload to calculate the hash key and query result as a data. This will work well for the data that is rarely updated and expensive to retrieve. Or in a scenario with the HEAD request, most likely you don’t want to execute the same query two times in a raw. Note: Always be cautious of cache lifetime and size.
By applying it you will avoid query execution and deliver query results much faster.
Another caching practice is an ETag HTTP Header utilization. This practice won’t allow you to bypass query handler execution but can reduce unnecessary network traffic.
ETag is a checksum that you compute from the Query Result and append to your HTTP Response. Next time client can append If-None-MatchHTTP Header with the checksum value it got from the last query execution. Finally, after a new query is delivered and executed, the new checksum will be calculated, if it will match with whatever is inIf-None-Match, the server will return 304 Not Modified HTTP Response with no additional data, notifying the client that data was not changed since previous execution. You might think it is not a big deal, but in an environment with heavy querying, this approach will significantly improve application user experience, as the client-side rendering library won’t need to process incoming data for new changes (detect changes and perform re-rendering).
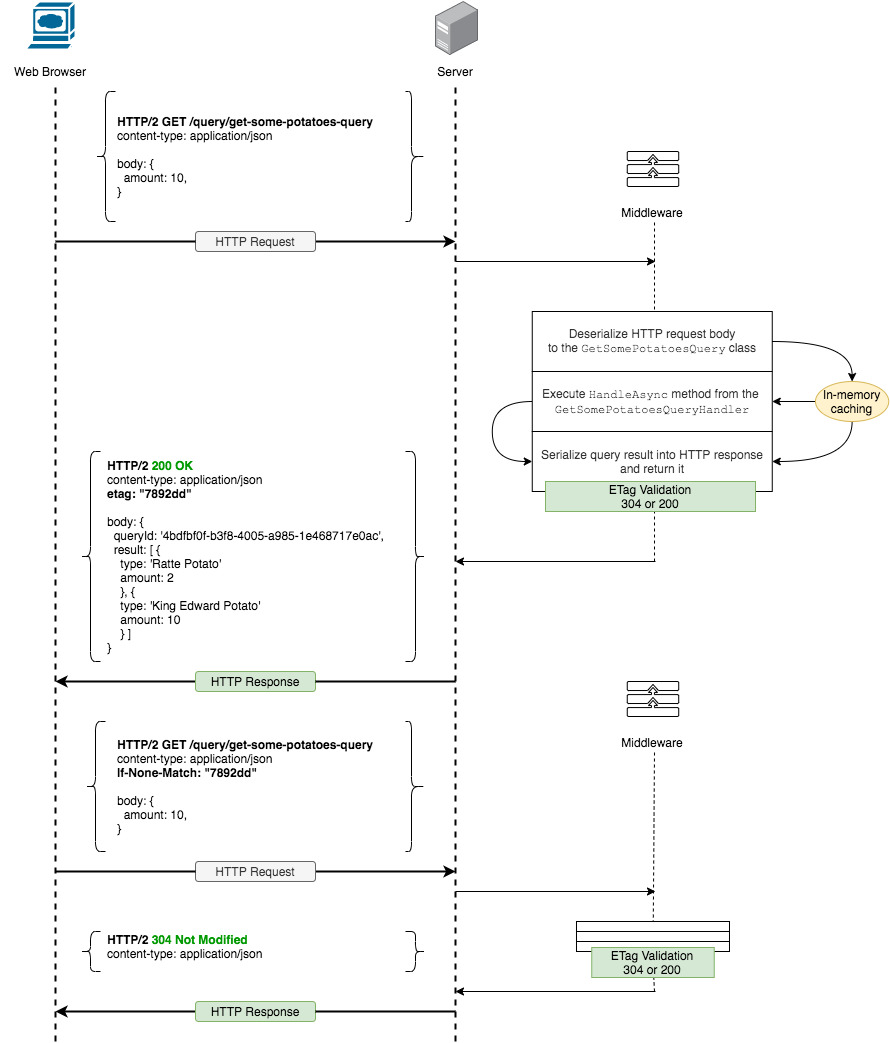
Combining and configuring these two strategies together can improve overall querying performance, hence user experience.
How To?
Most of the web applications nowadays follow Middleware pattern for establishing request/response workflow. The pattern itself represents a queue of callbacks. Each callback can react on the incoming request in its way (e.g. by mutating or adding something to the response). And may or may not pass the control further down the line to the next callback or terminate the processing chain. Potentially pipeline might contain conditions, and based on it branch out in different directions.
It is very similar to the real-world factory assembly line, where the end product is an HTTP response and workers are middleware blocks.

With the middleware pattern on board, it is fairly easy to apply a set of directives defined above to form the commanding framework.
HTTP Querying Middleware
Not a long time ago I’ve built a framework that is following this guidance and provides an easy-to-mount middleware, capable of handling large payload efficiently. It is called HTTP Querying.
Check out the GitHub repository and documentation or go ahead and plug it in your project ➡️ 