This article starts the series dedicated to CQRS on top of HTTP. We will be looking at the Command Query Responsibility Segregation pattern as an architecture, particularly dive into the Commanding part and try to find out how to fit it in the HTTP. At the time this article is written, two main protocol versions exist HTTP/1.1 and HTTP/2. Version 3.0 is in the draft, so we are not taking it into consideration. The main difference between 1.1 and 2.0 is the transfer layer. The semantics stays the same, hence everything we’ll be talking about here is relevant for both versions.
ℹ️ Don’t forget to check the introductory post to the CQRS pattern, where we’ll go through the idea behind the pattern as well as main actors [CQRS: Inro].
Check all available articles dedicated to applying CQRS architectural patter on top of HTTP [CQRS via HTTP].
If you are looking at CQRS as an option for your current or next project, you are on the right track, make sure to go through another important aspect of CQRS pattern, such as Querying.
In the previous article, I’ve identified the main features of the Command as a part of the CQRS pattern. Take your time and check it out, to get yourself familiar with the CQRS pattern. I’ll quickly highlight main features here:
- A command is an intention, not a fact. Depending on if all conditions were met, it might either succeed or fail.
- Command execution is an indivisible process. It has a transactional nature. Each command must succeed or fail as a complete unit; it can never be only partially complete.
- In the end, the command execution process should provide feedback on whether it was successful or not. Thus, after complete execution, each command process might have one of two end-states, succeed or failed. And overall one of four states executing, succeed, failed or terminated (e.g. exception was thrown during execution).
Why and When?
Since we are talking about more concrete implementation and choice of an architectural pattern it is important to illuminate CQRS strengths against others. As an opponent, we’ll look into one of the most popular architectural patterns for web applications, the Representational State Transfer, or just REST. More specifically HTTP based RESTful API.

I found three major reasons, which play in favor of the CQRS pattern. And - at the same time - are good indicators for me whether I should use one or another.
CQRS is forcing us, as developers, to think of user intentions and build task-oriented design, pushing developers to look deeper into the domain, use knowledge crunching more eagerly. Build conversations around the tasks that the user attempts to accomplish. While for REST Web Services the first-class citizen will always be the resource and its permutation.
With lots of benefits, REST comes down with some sacrifices. One of the main pitfalls is its interaction vocabulary limitation. The HTTP has a definite set of request methods. Nine (Eight and a PATCH). And those are leavers for the resource manipulations. There’s only so much you can do with each resource. It puts a frame on your modeling freedom. What if your application, the domain is not that simple and it doesn’t fit in this frame. You need to have a more arbitrary set of operations. This is where CQRS unties your arms.
I’m not going to discuss Event Sourcing in detail here. But whenever I think it is beneficial to use it for storing application state, my choice of wrapping pattern, if I may say so, would always be CQRS. CQRS and Event Sourcing play very well together and build a great symbiosis.
HTTP Request
To start the process we need to construct an HTTP request message, which will perform as a Command. We will start by choosing the appropriate request method. As stated above, there are 9 available HTTP request methods. Some of them can be eliminated from the start. Such as GET and HEAD, which are so-called safe methods and used for data retrieval. Next on the elimination list are PATCH, CONNECT, OPTIONS, and TRACE. These methods won’t work by definition, their purpose doesn’t match with a Command in any way. PATCH is used to apply the partial modification. CONNECT is a reserved method name for use with a proxy. Not getting in too many details, OPTIONS and TRACE inherit one feature that will inhibit these methods from representing a command, we’ll touch it in a minute.
Idempotence
So far we have eliminated everything except two methods. POST and PUT. Both seem to tick all the boxes and might be interpreted as a good candidate for accompanying command data in the request message.
The significant difference in this context is idempotence. The PUT method represents the idempotent operation. Can we guaranty that command execution will be idempotent? Implementation of the command handler is after the consumer and there are no guarantees that the handler will be idempotent, hence no guaranties the process will be idempotent. Therefore we can eliminate the PUT method. This is the same reason OPTIONS and TRACE methods won’t work.
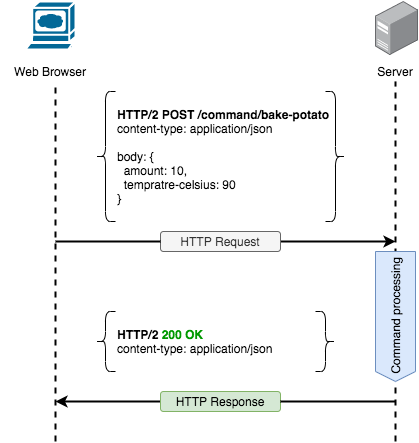
Hereafter the POST HTTP request method is the best to send Command with.
Command Name

The command itself consists of two distinguishable data components. The name and the payload. Technically name is part of the command payload. However the name is the only mandatory part of the command data and it will always be used for the same purpose, to instruct the server how to process the rest of the data.
From first glance, there are two good places for transferring command names. The content-type header field and URI. Let’s look at the content-type first.
The “Content-Type” header field indicates the media type of the associated representation: either the representation enclosed in the message payload or the selected representation, as determined by the message semantics. The indicated media type defines both the data format and how that data is intended to be processed by a recipient, within the scope of the received message semantics, after any content codings indicated by Content-Encoding are decoded.
Taken out of context, the underlined part of the RFC 7231 quote “… and how that data is intended to be processed …” might sound almost like an instruction for using content-type as a place to store command name. Yet after careful read, we’ll find it is not. I like to think of the content-type as of filename extensions in the operating system. The characteristic of the file contents. In the case of the HTTP request, it should be characteristics of body contents. Its MIME type.
From the HTTP perspective, it is fair to look at the commands as an abstract resource. Hence we can legitimately specify a command name in the URI path fragment. Command to buy more potatoes will look like command/buy-more-potatoes.
Command Data
Command plays two roles, it acts as a signal, to start some sort of procedure. And it might or might not carry a payload which will enrich the signal.
In the POST HTTP request method, data suppose to go in the message body. I could not find any reason to challenge this. As mentioned above, the content-type header will tell request processor which type of data suppose to be there, is it XML, JSON, etc.
A sender that generates a message containing a payload body SHOULD generate a Content-Type header field in that message unless the intended media type of the enclosed representation is unknown to the sender. If a Content-Type header field is not present, the recipient MAY either assume a media type of “application/octet-stream”
HTTP Response
As been claimed in the beginning, the successful command execution process should return either a successful or failed state. Additionally, we might want to provide failure reasons. Let’s start with the first part.
The first line of the HTTP response is the so-called status line, which consists of a protocol version, status code, and status text. This is something we may use for feedback. Independently of the HTTP version, the set of status codes stays the same. It is a strictly defined list, segregated into 5 groups.
- Informational responses (
100–199), - Successful responses (
200–299), - Redirects (
300–399), - Client errors (
400–499), - Server errors (
500–599).

Keep in mind that potentially we can extend this list and return something like 606 - Potato Not Found and it won’t be considered as protocol violation, as long as the client understands it. However, let’s try to stick to existing codes. It makes sense to use something from the second group (2xx) if the command successfully executed. While in case of failure we will notify the client that we could not perform the requested action, something from group number four 4xx should do the job.
In case if the command was executed successfully 200 - OK looks like the best status code for the purpose. It indicates that the request succeeded. Which makes total sense when command successfully executed.
The last unresolved scenario is a response that will encapsulate the command execution failure due to the current system state or other unmet conditions. There are few potential candidates in the list, such as 406 - Not Acceptable, 422 - Unprocessable Entity or 409 - Conflict. However 406 will work better for occasions when sent command is not supported, 422 is more about corrupted payload. Finally, 409 seems to be a good fit for the purpose.
The 409 (Conflict) status code indicates that the request could not be completed due to a conflict with the current state of the target resource. This code is used in situations where the user might be able to resolve the conflict and resubmit the request. The server SHOULD generate a payload that includes enough information for a user to recognize the source of the conflict.
409 response code should be supplied with enough information for the client to fix the root cause of the problem. That makes absolute sense in the context of command execution response.

How To?
Most of the web applications nowadays follow Middleware pattern for establishing request/response workflow. The pattern itself represents a queue of callbacks. Each callback can react on the incoming request in its way (e.g. by mutating or adding something to the response). And may or may not pass the control further down the line to the next callback or terminate the processing chain. Potentially pipeline might contain conditions, and based on it branch out in different directions.
It is very similar to the real-world factory assembly line, where the end product is an HTTP response and workers are middleware blocks.

With the middleware pattern on board, it is fairly easy to apply a set of directives defined above to form the commanding framework.
HTTP Commanding Middleware
Not a long time ago I’ve built a framework which is following these guidance and provides an easy-to-mount middleware, capable of handling large payload efficiently. It is called HTTP Commanding.
Check out the GitHub repository and documentation or go ahead and plug it in your project as a ➡️ 