I feel like data storage scalability in distributed or not systems is often overlooked.
Whenever we talk about scalability, we usually imply processing scalability in distributed systems. We talk about ways to scale out dedicated service clusters without downtimes or data flow interruptions.
I’ve written a few articles about it myself. Don’t forget to check them out afterwards
But today, let’s talk about data scalability. How can we efficiently handle massive data sets without downtime or performance implications?
Partitioning (aka Sharding)
If we take any arbitrary architecture and zoom in close enough we’ll see that there’s some sort of database running on the server (either physical or virtual).
Surprisingly enough databases don’t work that well with rapidly growing data. Any growing data set eventually reaches the pivotal point when it becomes large enough to start impacting database performance. The database will hang in for a while until the actual physical storage limit is reached. E.g. literally SSD is full.
This is where scaling kicks in. There are two dimensions to scale: vertical and horizontal. Vertical is finite and exponentially expensive. So generally horizontal scaling (aka scaling out) is preferred. In essence, we just keep adding more and more database servers as the data set grows larger and larger.
To take advantage of new servers we need to start distributing the data and have a way to find it afterwards. The process of splitting the data set horizontally is known as sharding. In a given context sharding and partitioning are interchangeable terms.
Sharding is commonly used in distributed databases like DynamoDB or Apache Cassandra. For Content Deliver Network (CDN) implementation. And keeps running services like Netflix, Discord, Vimeo and whatnot.
There are multiple ways to implement sharding. We’ll start with some basic partitioning practices and techniques and build our way up toward more widely used and sophisticated ways to implement partitioning. This way we will understand common challenges in partitioning implementations and illustrate justifications for the complexity that comes with some more advanced partitioning techniques.
Setting up the scene
Let’s set up an imaginary example. I’ll use this example to illustrate different partitioning techniques, and their pros and cons.
Our application has been around for a while and now we have a continuously growing data set of 10 million users. Each user record might have arbitrary information. However, each user record has an email field. We use user email as a unique identifier for the record.
So the data set would look something like this:
|
|
Because our data set is large enough, we’ll say our starting target cluster size would be 3 nodes (either database or cache servers). Hence we need to partition and distribute the data between them.
Non-hash Partitioning
We’ll start with partitioning techniques that don’t require hashing. These are arguably the most primitive ways to approach partitioning. Nevertheless, they are good contrasting points for hashing examples
Key-Range Partitioning
As the name suggests we will first nominate a unique field to be the key and then we assign a range of keys to each node. The assigned range will be stored in some sort of a map, hence the lookup for a Node would take O(1) time.
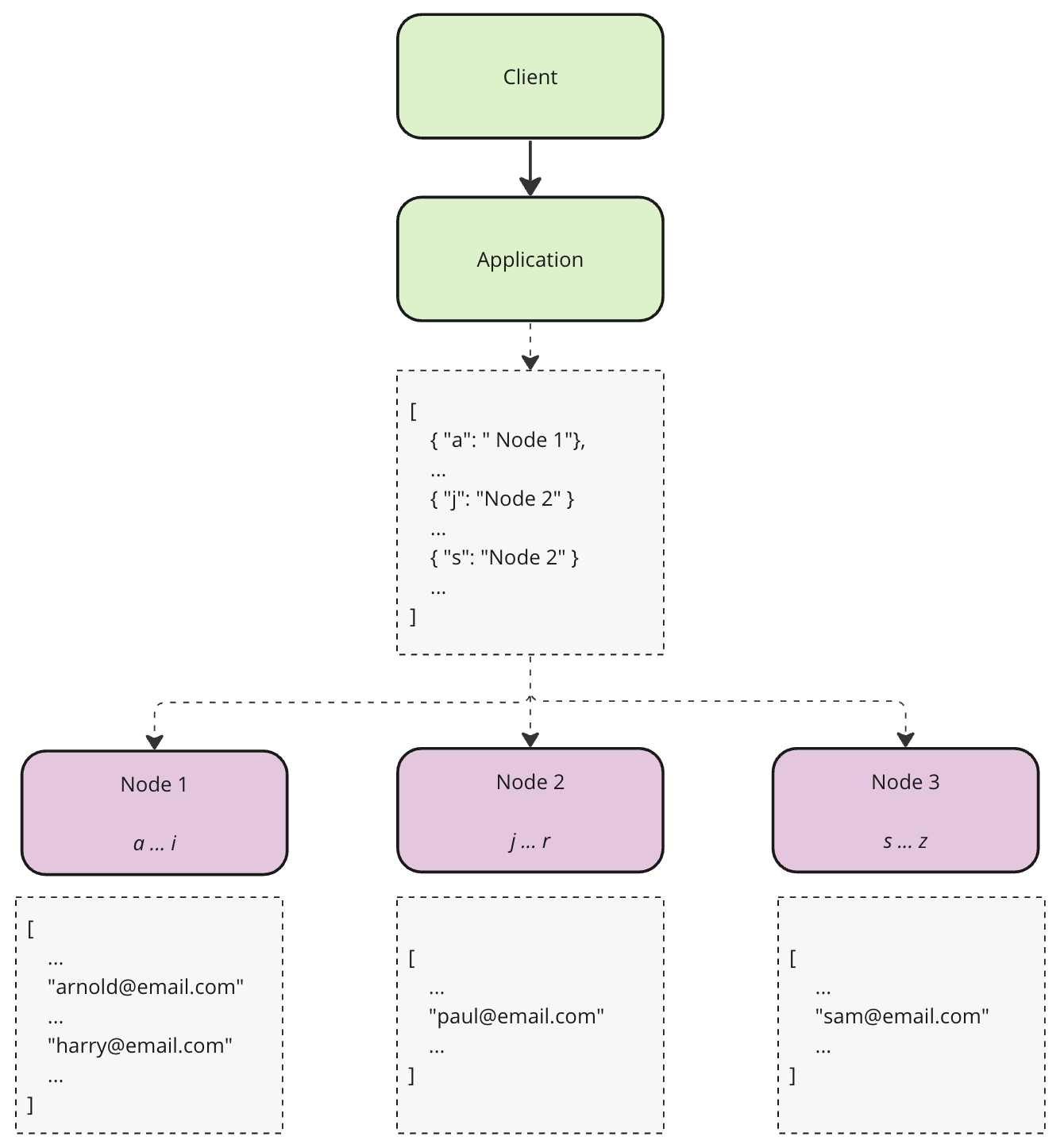
Unfortunately data distribution will be uneven. E.g. certain letters will occur more frequently, thus creating hotspots and ultimately sending us back to the initial problem.
Random Partitioning
No surprises here either. This technique is similar to the previous one, except in this case, we will randomly pick a node for every record. Which potentially might help us distribute data more evenly but creates another problem. Because we don’t know where data is the lookups will take at least O(n) time. Given we often need to perform lookup for both read and write this option doesn’t look too appealing.
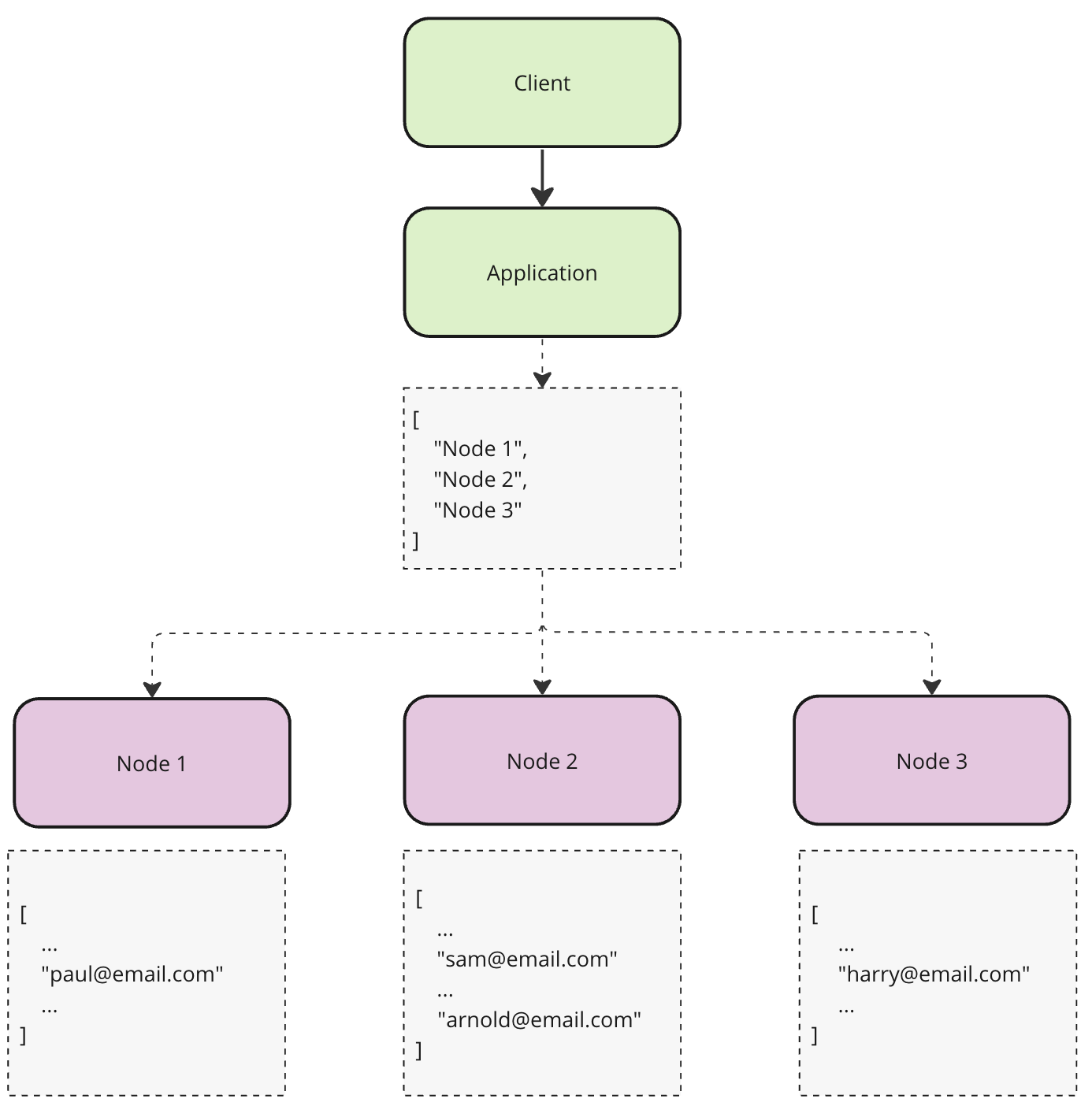
Hash Partitioning
Hash partitioning techniques we will be looking at will not surprisingly involve hashing functions and modulo operation for the key calculation and lookups. So before jumping in make yourself familiar with both.
Static Hash Partitioning
The foundation of static hash partitioning is in the consistent reproduction of a target node from the key. In other words, if the same key is given twice or more it will always point to the same node.
Remember our user example? Let’s look at how key calculation and distribution/lookup might look alike first.
We have 3 nodes. And we want to store the record with the key arnold@email.com. The process will consist of two steps, we calculate a hash of a given key to get a numeric representation and take a modulo of the total amount of nodes minus one, to make sure we distribute the key within the range of nodes we have.
|
|
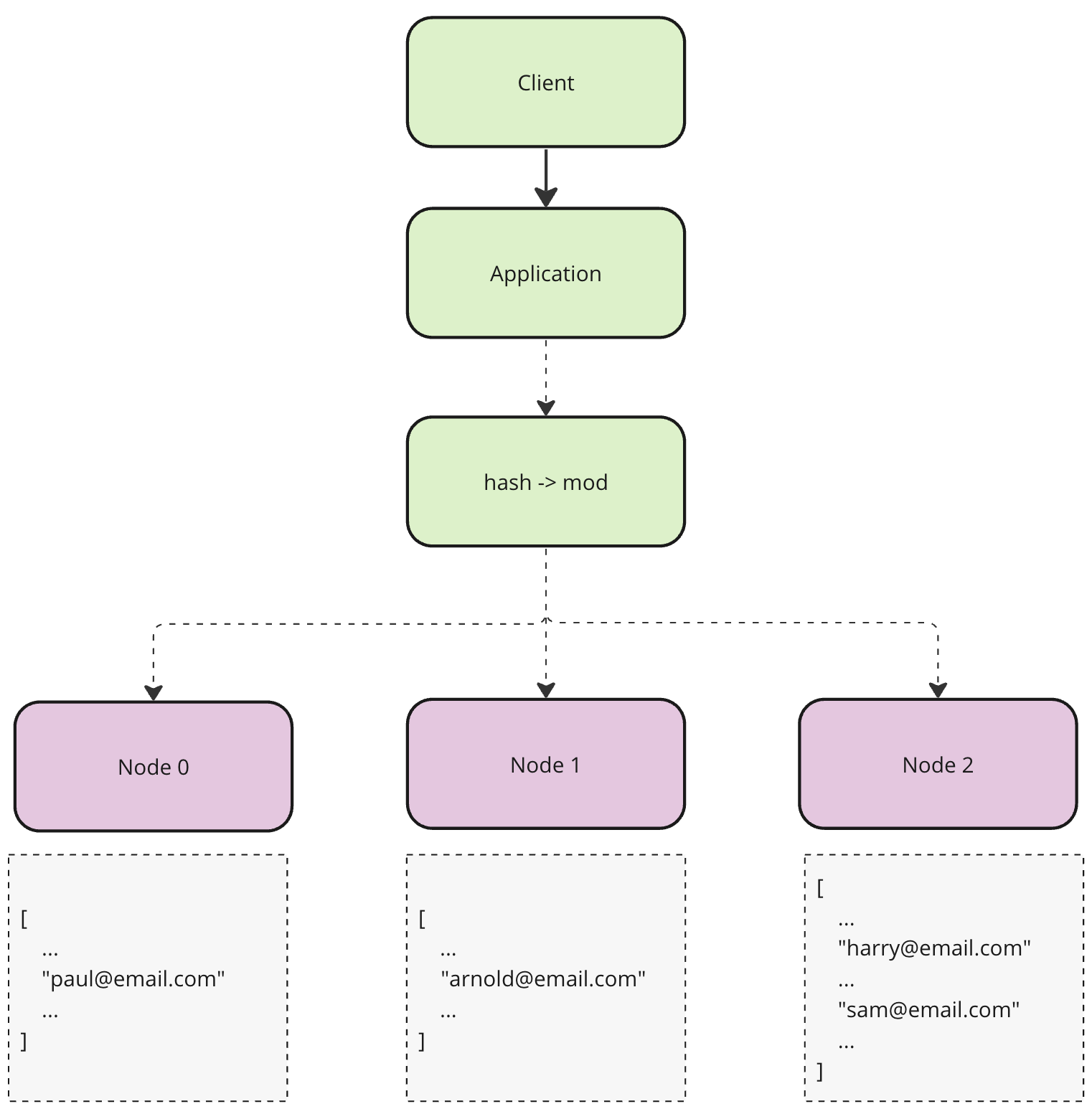
Even though static hash partitioning seems to achieve better distribution and lookup complexity is O(1) it has one important flaw. It is not scalable. Or should I say it is scalable but very expensive. Since target node calculation depends on the total amount of nodes, adding or removing a node will invalidate previous distribution. Hence the whole data set must be re-distributed, which will result in downtime and overall sluggishness.
Consistent Hash Partitioning
Consistent Hash Partitioning is a sort of re-thought of Static Hash Partitioning.
Instead of relying on the total amount of servers Consistent Hash Partitioning introduces a looped virtual address space. It is not as scary as it sounds, once we will draw it out, it will make much more sense. The best way to imagine it is a circle or a ring. Often it gets referenced as a hash ring. Let’s say we have a hash ring of size 128.
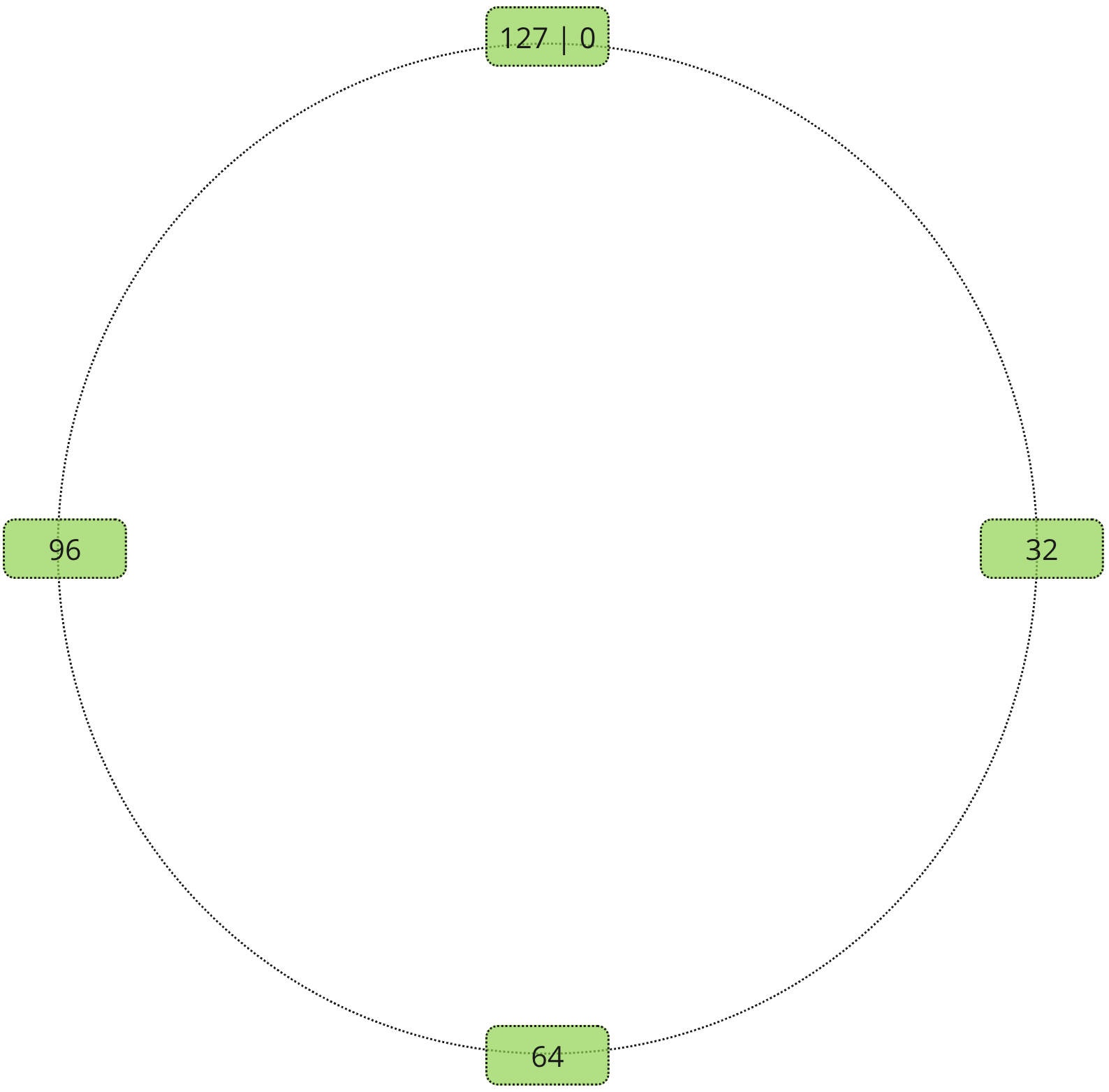
Record receives an address on the hash ring using a similar process as Static Hash Partitioning. Except the modulo calculated based on the largest possible address.
|
|
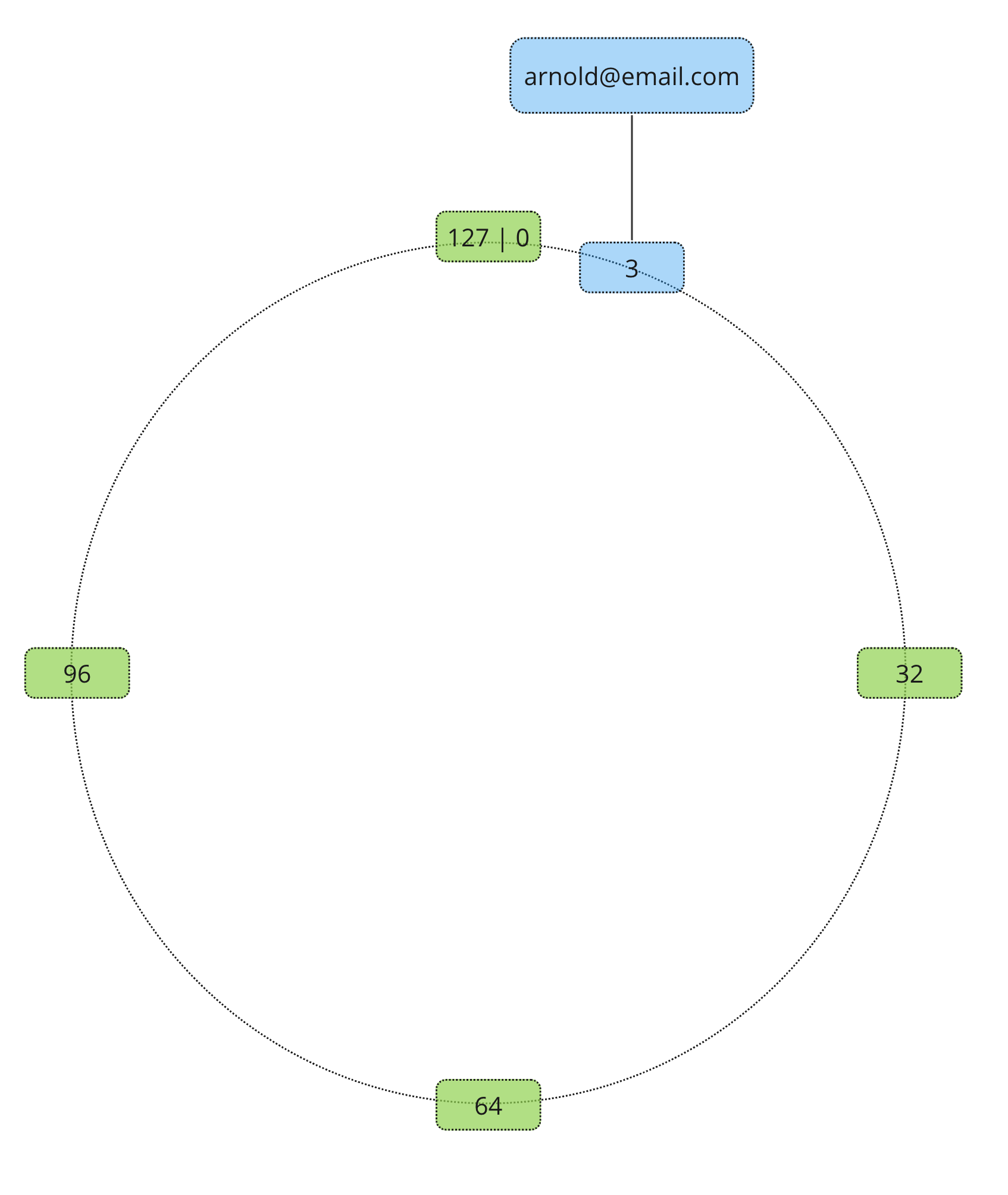
What about nodes? Well, nodes also receive addresses based on their own unique identifiers (e.g. hostname or IP address).
|
|
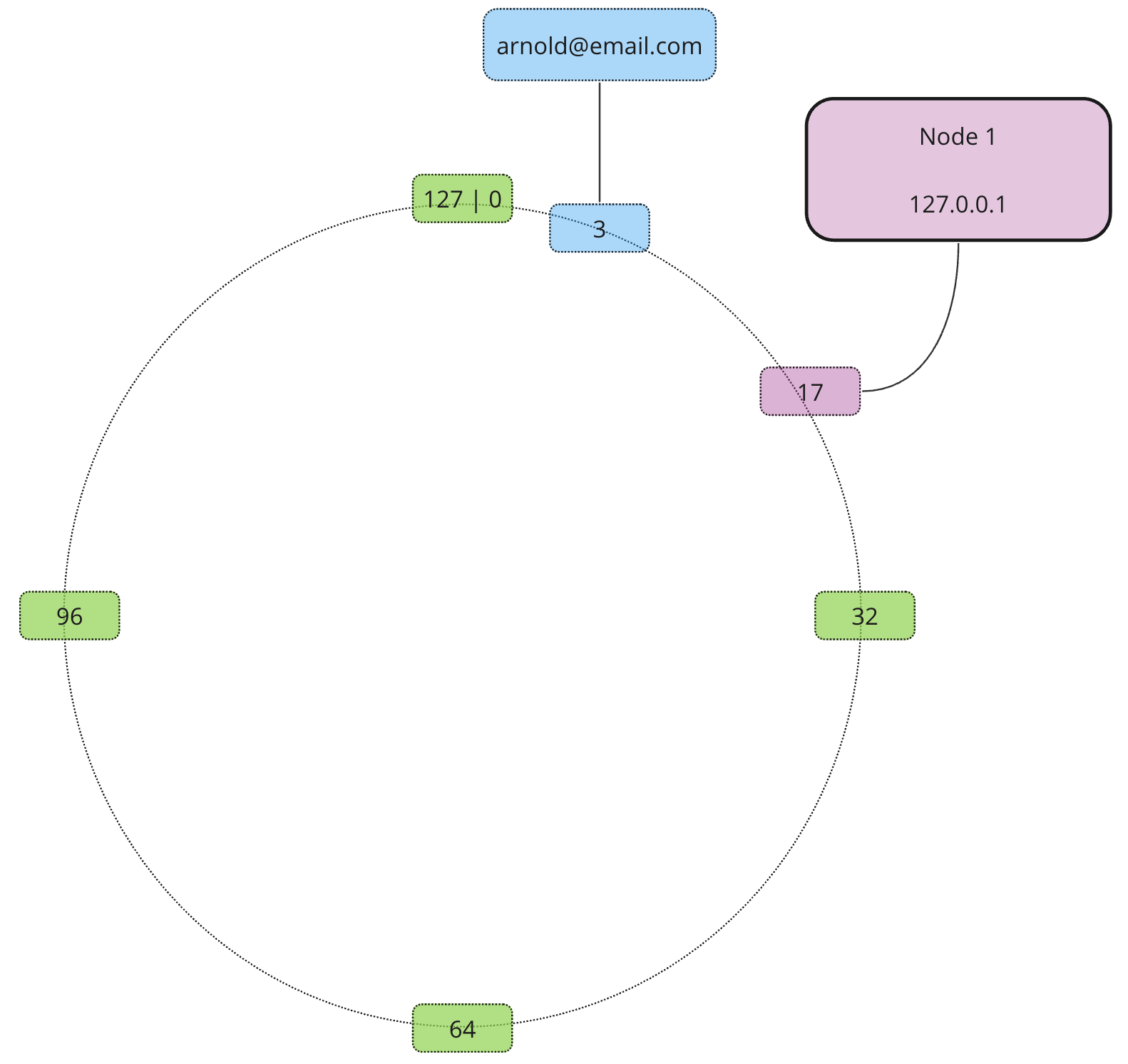
Using the same approach we add the rest of our nodes…
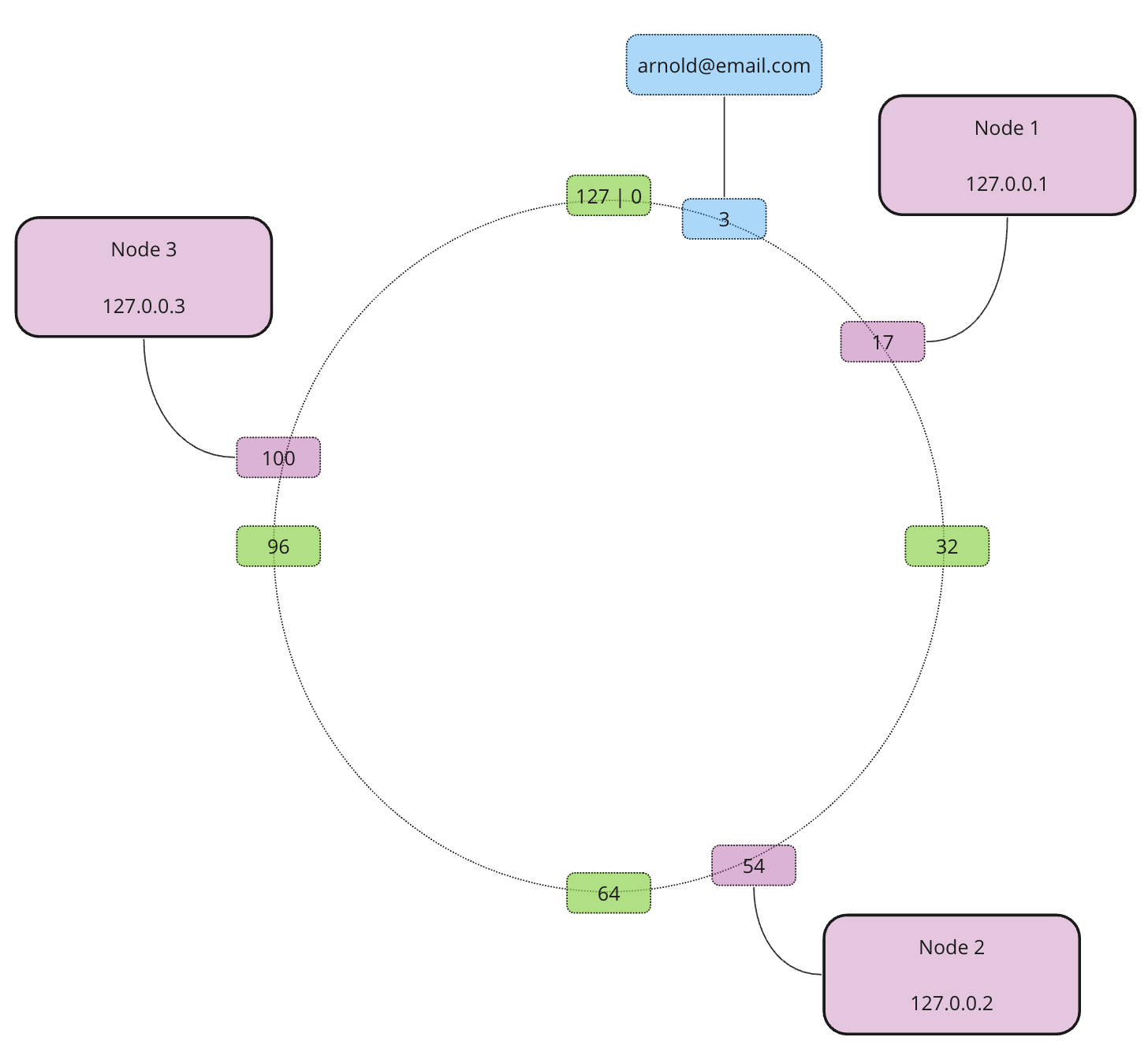
Now we have 3 nodes and one record. Which node does the record belong to? Depends on the allocation direction. It doesn’t matter which direction to choose as long as it is consistent all the time. Usually, the allocation happens clockwise. This means that the record is allocated to Node 1 as this is the closest node in the clockwise direction
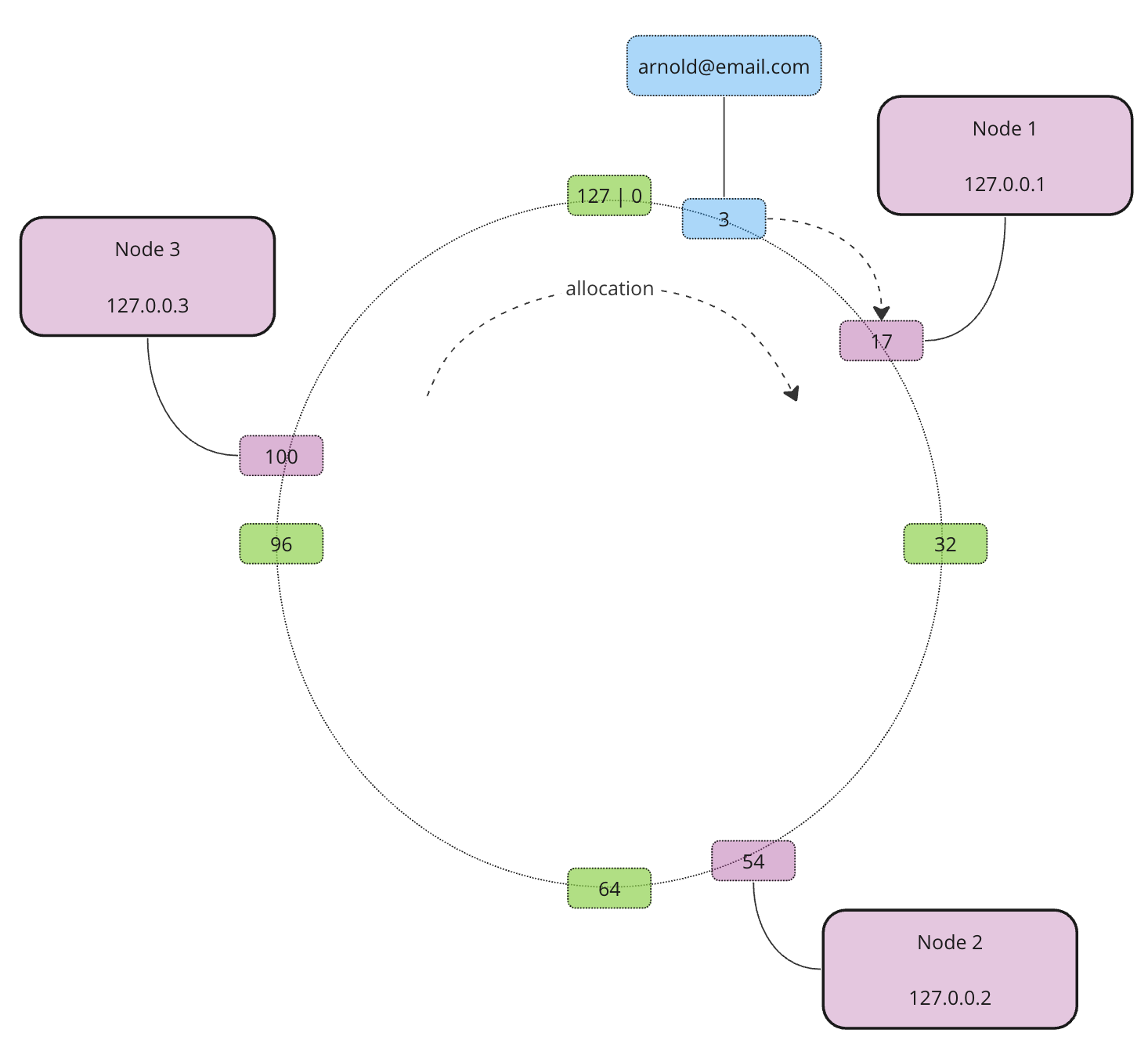
Now let’s allocate the rest of the records
|
|
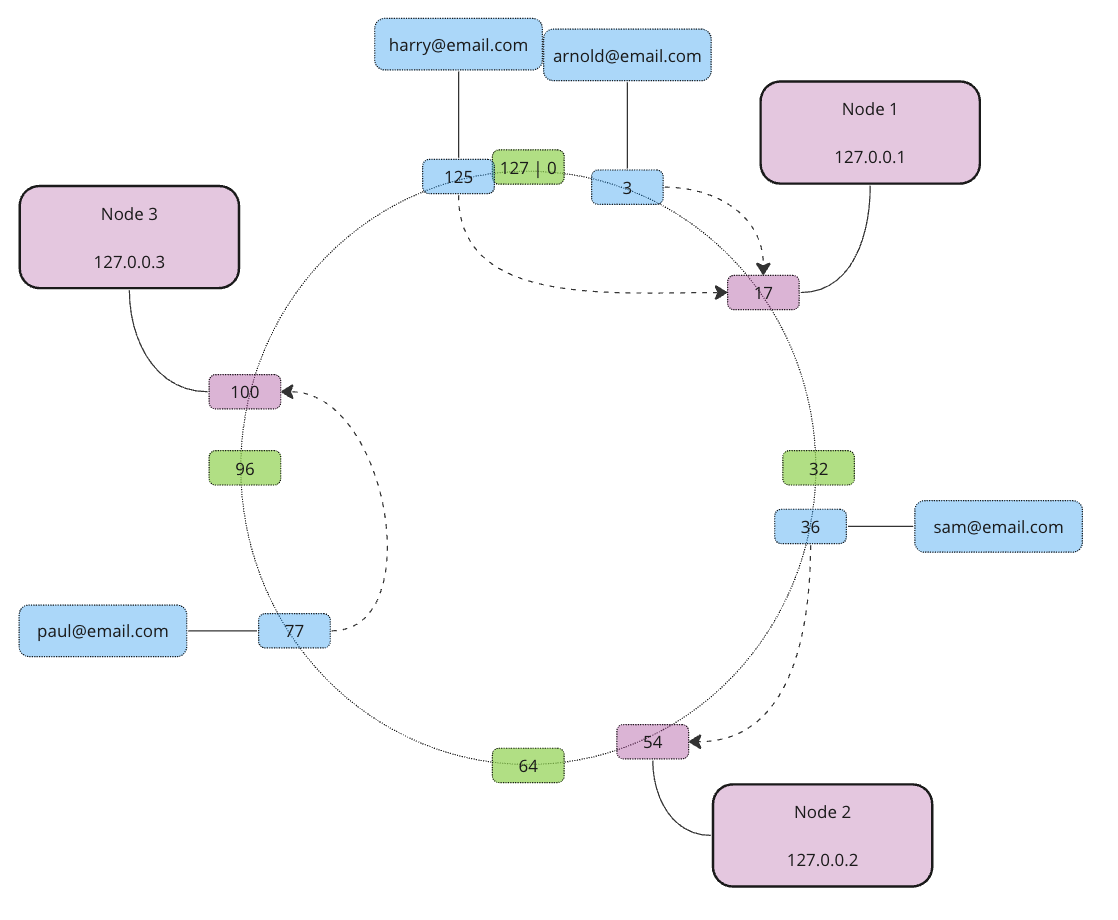
So far so good. Now let’s see what will happen if we add or remove a node. Let’s say Node 2 fails and becomes unavailable. In this case, we only need to redistribute the data set from Node 2, actually, we simply move it to the next node in a clockwise direction.
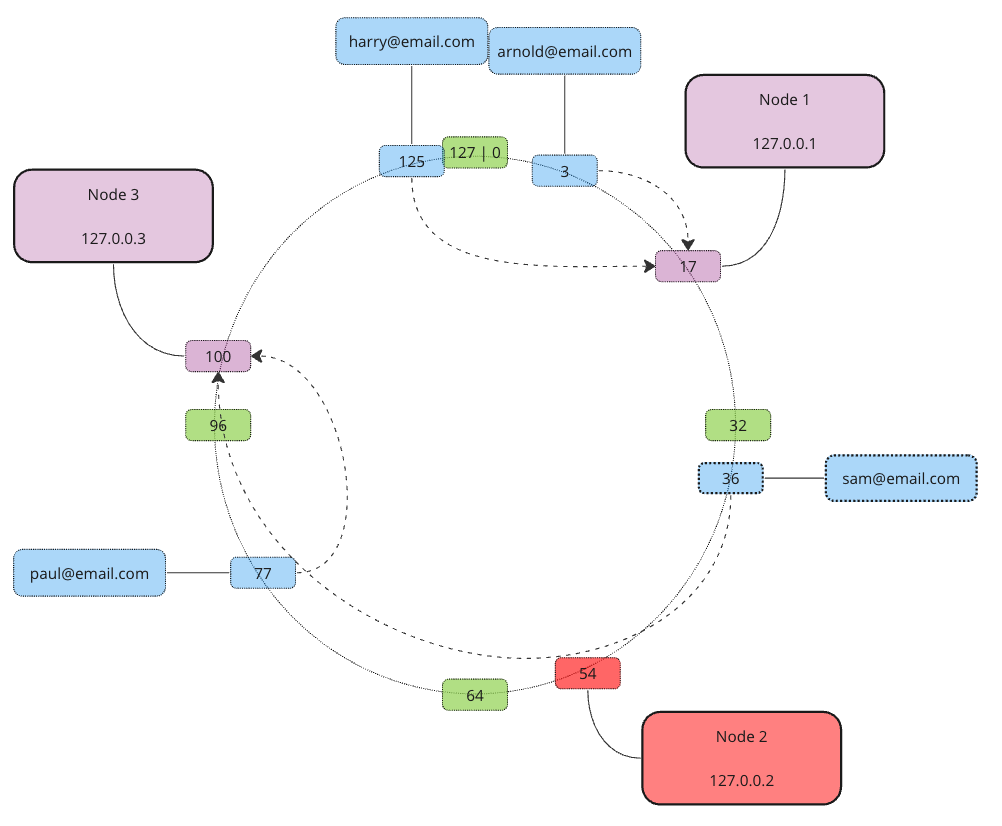
Now what if we scale out and add an extra node… We simply take all data from its next neighbor clockwise until the new node’s own address… In our example, Node 4 will take care of everything between addresses 55 and 80.
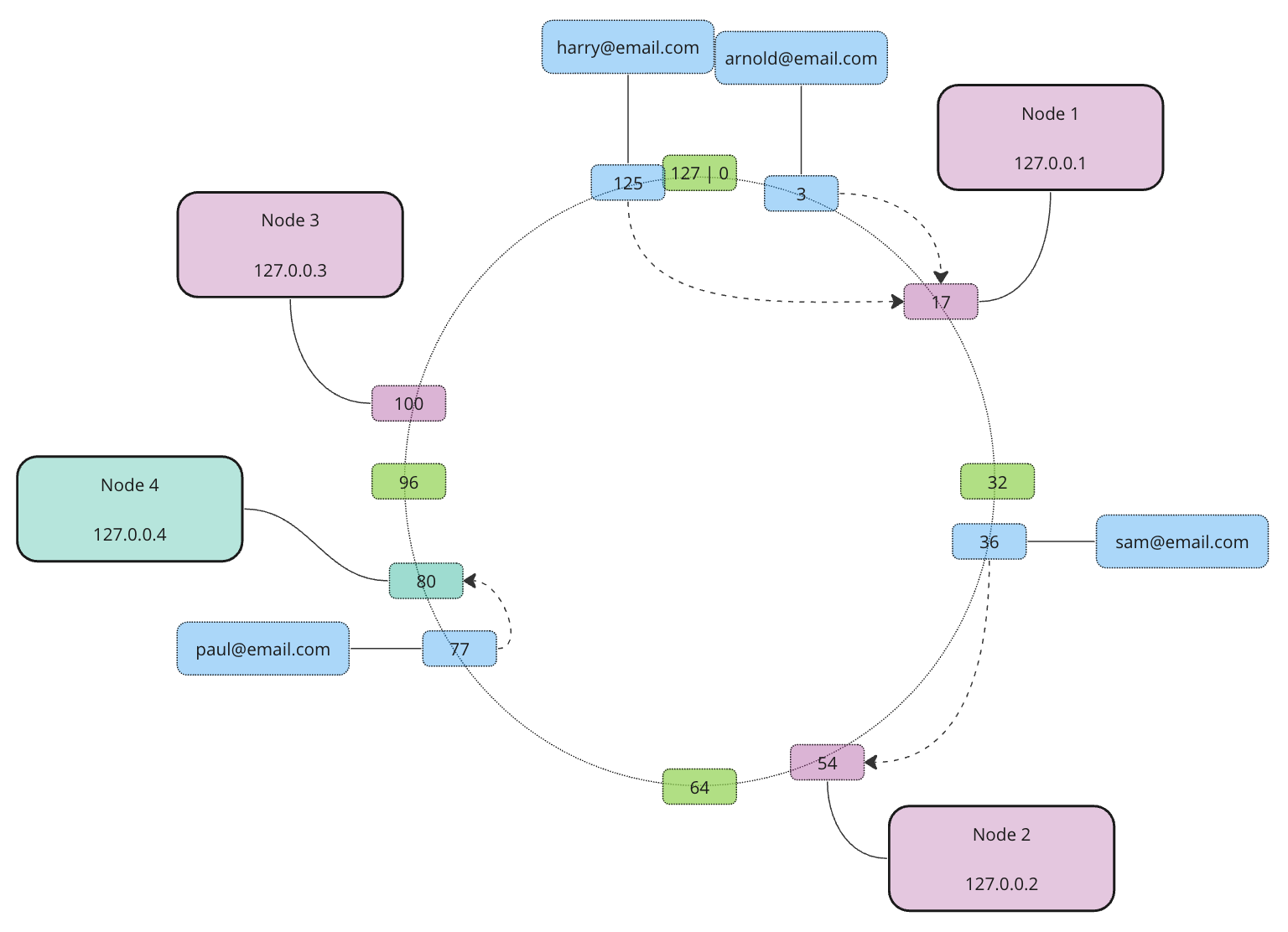
Re-distribution is pretty straightforward and requires the re-allocation of data only for a single node.
Virtual Nodes (VNodes)
Scaling doesn’t seem to be a big problem here, nevertheless, there are still some weaknesses left. This approach will suffer from now familiar to us problem. Uneven data distribution. There’s a good chance hot spots will occur and overload some nodes creating hot spots. Especially in case of a cluster fuck outage, when multiple nodes fail at the same time.
The good news is there is a solution, but before we jump into it let’s revisit how address ranges are assigned again, but from a different perspective, with some colour coding. Each node sort of owns an address range between its predecessor and itself.
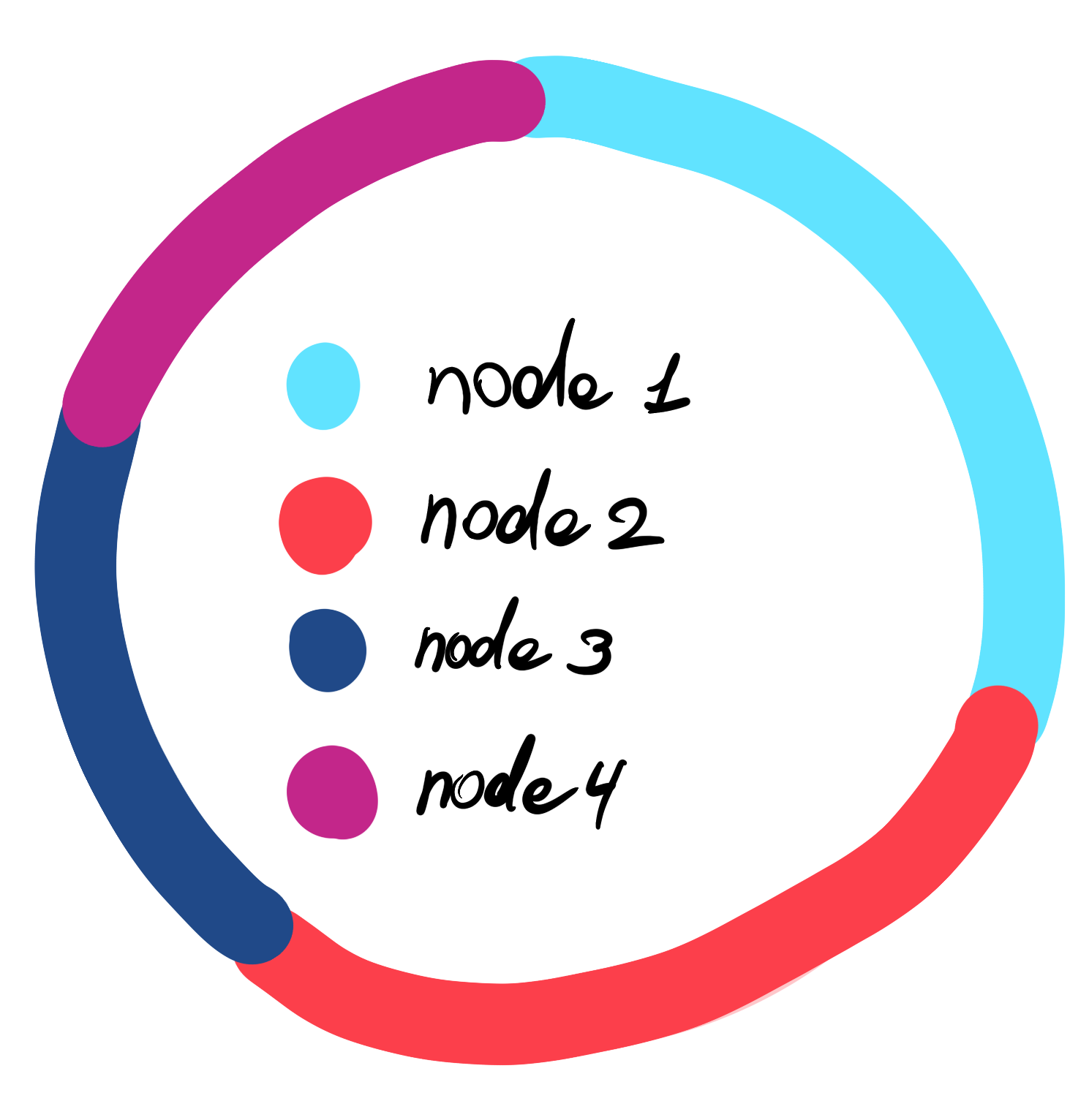
To make sure we evenly distribute the data (even when outages occur) we split each node into a certain amount of virtual nodes. We do it by applying different hash functions to the node’s unique identifier producing different addresses for each virtual node. Similarly to regular nodes, each virtual node will “own” an address range between itself and its predecessor. This approach prevents continuation in ownership and re-occurring neighboring patterns. Hence even when a cluster outage of virtual nodes happens following the master node outage, re-destitution won’t crate hotspots.
Thoughts
This is not an exhaustive list of ways to partition large data. Nevertheless, the most popular techniques will involve hashing in one way or another. Even though Consistent Hashing is a quite popular option used in practice, there are other alternatives. Such as Rendezvous Hashing which is used in Apache Ignite.
Even though it is not directly related to the partitioning, I thought it would be worth bringing it up anyway. Just to give a broader context and define boundaries. The application that uses a partitioned data store (whether it represents a cache or a database), shouldn’t know whether it uses a partitioned data store or not. From the application perspective data store is a single whole.
Another thing important to note is backups/replicas. Usage of any sort of partitioning does not eliminate the need to back nodes up, so in case of an outage, we would have a source for data to re-distribute.