It is not a guide for building a single page application with the help of React JS.
This article is about the tool that empowers modern web to look the way it looks today and provide a seamless experience of navigation, enabling single page applications to exist.
Good old days
Back in the days, the internet and everything around it was different, as well as expectations from web sites. A typical web site would be a set of HTML pages tied together with cross-references.
Occasionally some fancy web sites had JavaScript on few pages, primarily for decorative purposes. Not much was going on there, mostly callback hell.
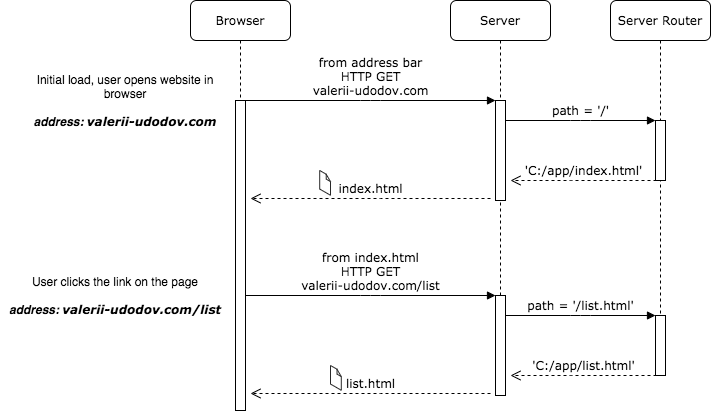
User experience for the web wasn’t a thing, at least not as big as it is now. The site navigation was quite primitive, you click on the link, and you are navigated to another page. The real physical page, that is stored separately on the server. Thus before showing the page to you, the browser had to request it and wait for it to arrive. After a while user would see a blink following by the desired page.
The module that is responsible for providing a correct page per request is the server router. Its configuration is fairly simple. You configure route mapping on your server and… And that’s it, you are done.
Here is how typical navigation flow would look like.
Single Page Application
The internet went a long way since then. In an ongoing fight between desktop and web applications, the last one started to dominate after it was able to provide the same look and feel as its predecessor did.
Nowadays modern web applications usually try to avoid interruption of the user experience and dynamically replace pages, avoiding the necessity of going back and forth to the server. This sort of application called a single-page application (SPA). To make dynamic page replacement possible, a SPA must have some sort of router with configurable mapping. The mapping might be a path to a component, path to view, a path to you name it.
To save developed user experience and native browser behavior, client-side routers have to use the same source of truth as server-side routers do, the URL path.
The evolution brought us a vast variety of capable frameworks. The majority can serve as an SPA platform. Despite the choice of the framework, it will most certainly use one of the two major mechanisms to implement client-side routing.
Hash Routing
First, and the most popular one is the so-called hash routing. The whole approach is built on top of utilizing a hash sign in the URL, specifically utilizing JavaScript window.location.hash property which returns everything after hash sign in the URL.
Stepping back turns out the original idea of having the hash sign in the URL and therefore in the window.location was to provide a way of anchoring to a certain place on the same page you are now. Imagine, you have a big HTML document, and you want to provide some sort of table of content. Add hash-anchors and voila, now you can navigate through your page without reloading it.
The cool thing about it is that you can share the link with a hash sign and this way, point a person to the exact paragraph you’ve been looking at. As you might guess at this point, everything after the hash sign was ignored and never ended up in the HTTP request. Even if you will try to refresh the page, it would load as usual, and after you will be automatically focused on the anchored location. No javascript involved, all out of the box. Magic.
As it often happens in the javascript world, this feature was not used by its purpose. Major frameworks started using it to facilitate their routing functionality.
In further examples I will use React, but you can replace it with any framework you like and diagram won’t change significantly.
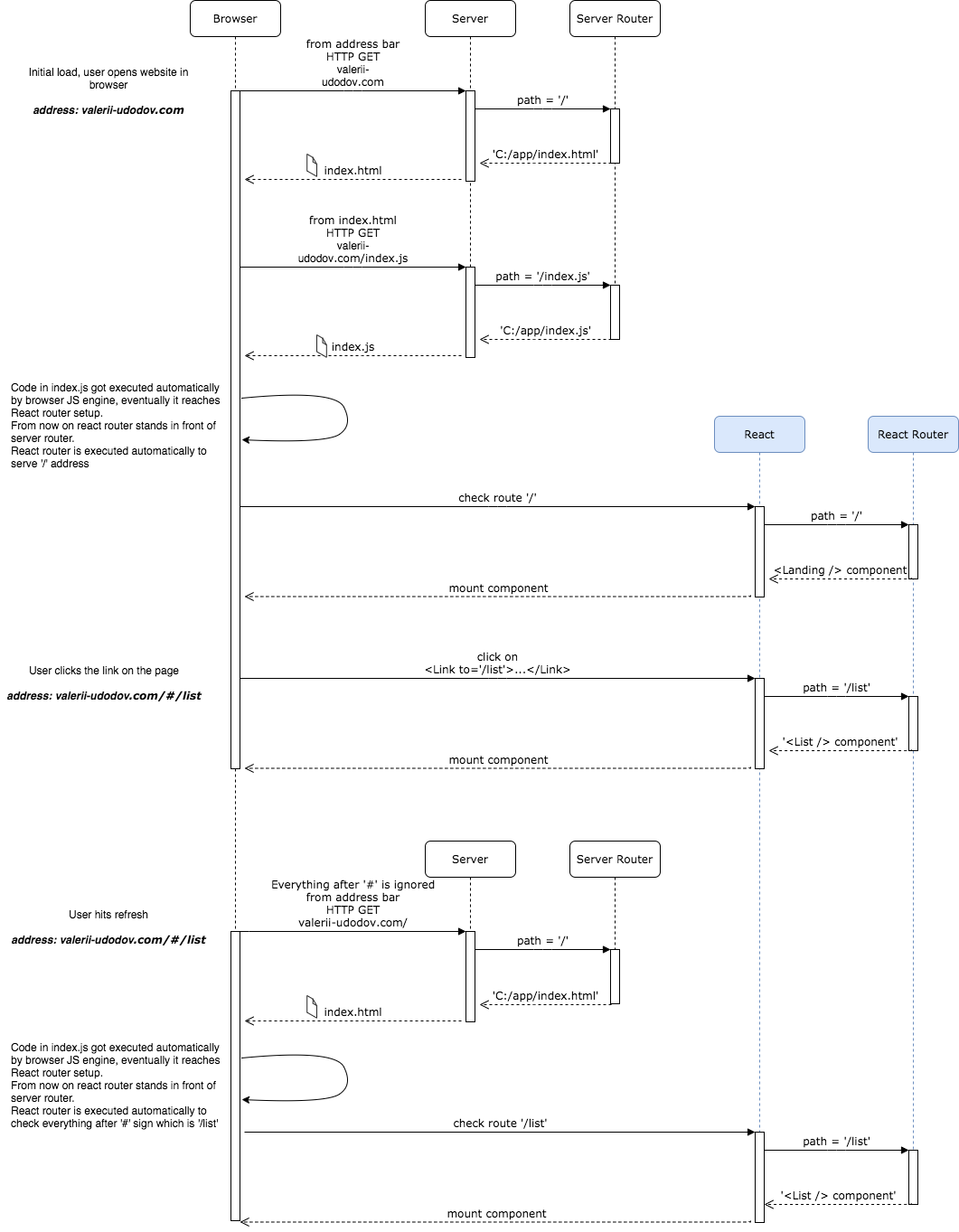
Browser Routing
Until HTML5 was released there was only one way to manipulate the URL programmatically, the one we discussed before, through window.location property. HTML5 introduced another way to do it, the History API. The main goal of the API is to provide a simple tool for editing browser history for the current session. Appeared that this functionality is exactly what was needed for routing, the API has a few functions to safely modify URL without triggering page refresh and a set of hooks to subscribe to the history changes.
It is not fully true, the API does not modify URL, it modifies the history. Think of the session history as of stack. A stack of URLs, the item on top is your current location, the item on the bottom is the URL of the first web site you’ve visited. History API provides a way to push items in the stack, which modifies your current location.
If you’ll open browser console right now, paste history.pushState(null, null, 'potato'); nothing except the URL path will change, further better, if you’ll hit back button you’ll get back to the original path of the current article, without any page refreshes.

And this brings us to another way of routing, the one that implemented with the help of History API. For React it has name of Browser Routing.
This routing has a hidden quirk. Since there’s no longer ‘#’ sign in the URL, the whole URL will be passed in the HTTP Request once the user hits refresh or shares the link. The server won’t know what to do with the path and return 404 Not Found HTTP response.
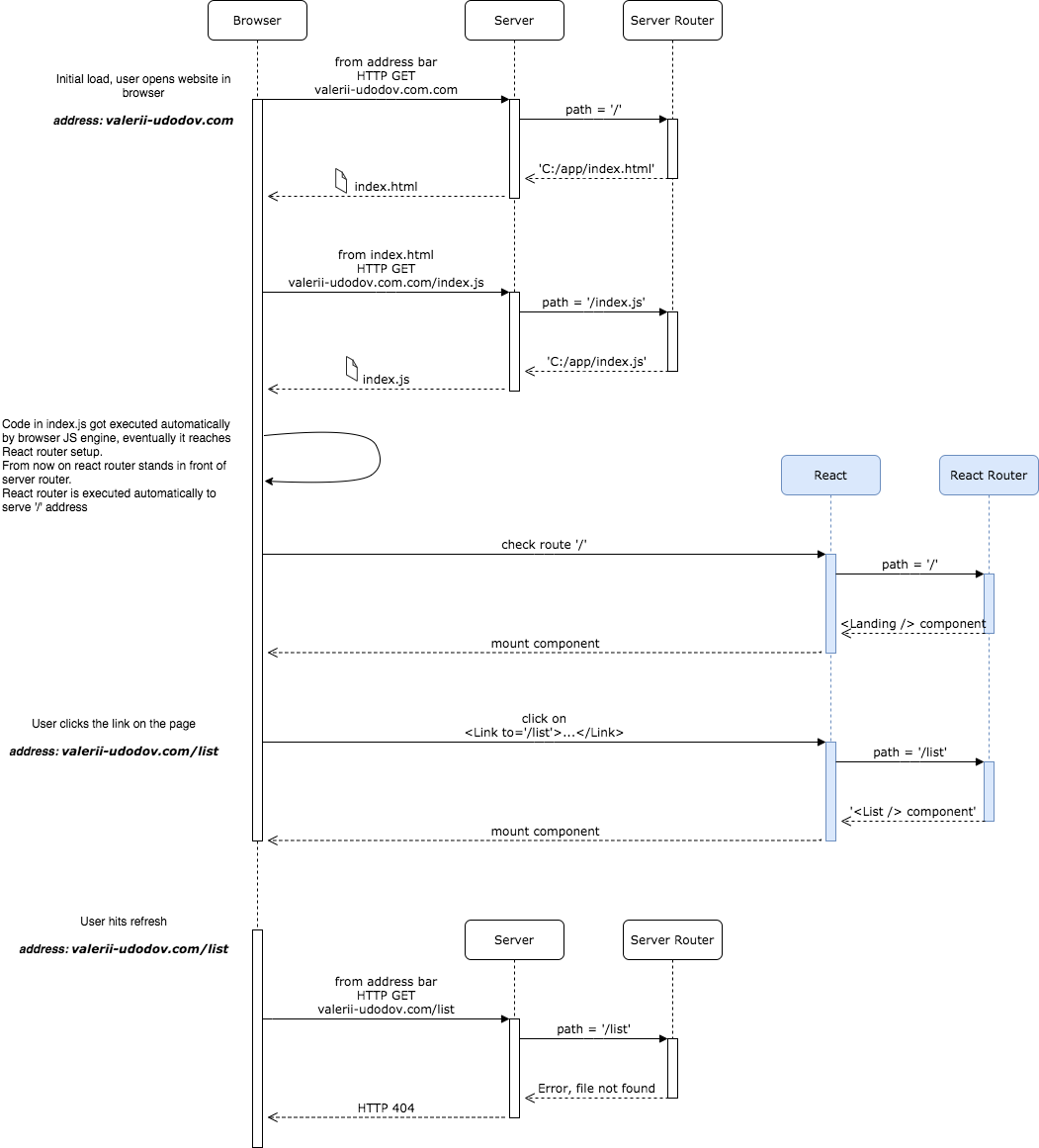
Now it is a good time to think of the expectations and responsibilities. Since we have a single page application, we don’t expect the server to do much with routing. Just provide us a single page, usually index.html, every time the request comes in, despite the URL path. The path itself has to be processed on the client-side by the SPA router once it is loaded and ready to roll.
Sounds easier than it is. Static website host providers rarely allow flexible routing configuration. Moreover, usually, there is some sort of fake server engaged in the actual development process. Hence we will usually have two different servers, read two different problems, which luckily can be solved with the same approach. And the approach is the fallback strategy, which has to be re-defined.
Every time the server router won’t find how to resolve the path, it should fallback to the initial page (e.g. index.html) and return it. This way it will allow the client-side router to take care of the URL path.
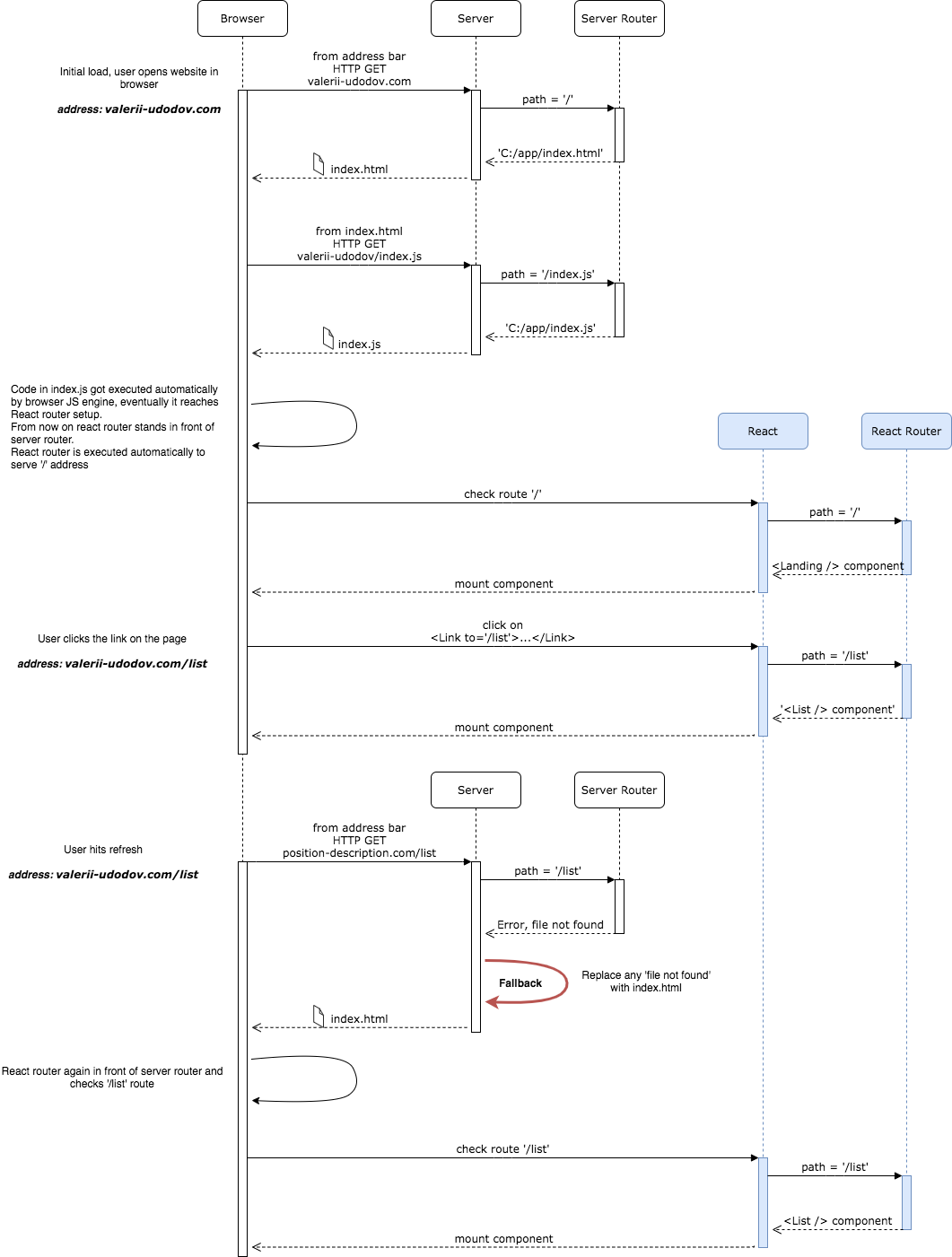
Note, that now the client-side router is responsible for handling 404 Page Not Found. If it is not handled by the framework of choice, a 404 page/component/whatsoever can be configured as the last item in the route mapping with path pattern that will satisfy any given path.
Examples
One of the most popular fake development servers is webpack dev server. It already has a built-in switch to manage fallbacks, just add a --history-api-fallback and there you have it. By default, it will fallback to index.html. However, this property is available as part of devServer webpack configuration and allows you to overwrite default behavior.
One of the most popular static web site hostings nowadays is AWS S3. It has an option to configure what they call error document, just place an index.html there and now you are all set.
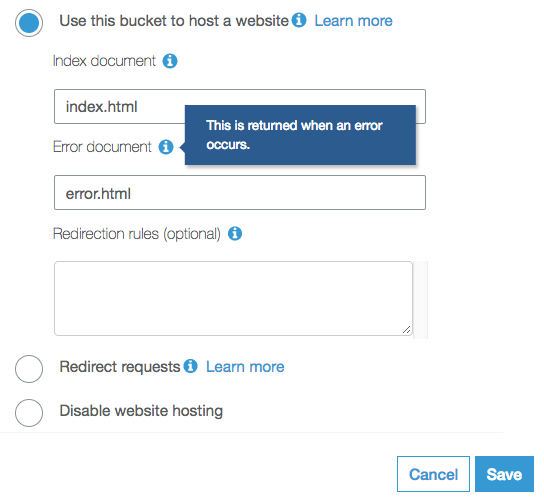
Provided examples don’t cover all possible cases, yet should give an idea of what to look for.
In the end
Among other tools and technics, client-side routing is something that makes a single-page application a real thing. In turn, the single-page applications bring user experience on the same level as desktop applications do.
There are two major approaches of how client-side routing might be implemented. Both them will work fine, however the Hash Routing, as I mentioned before, was originally built for a different purpose. So if you are planning to use page anchoring, I would recommend switching to the Browser Routing.
But in the case of the Browser Routing, you need to keep in mind that the page refresh and sharing won’t work as expected out of the box, and you’ll have to do some extra configuration to make it work. As an extra tick for the Browsing Routing, your URL path will look much nicer.
In the end I would recommend using a Browser Router where it is possible.