I’ll start this article with a quote that changed the way I think of memory. The way I perceive memory lifecycle in major modern languages (those that have automatic memory release aka garbage collection).
Garbage collection is simulating a computer with an infinite amount of memory.
– Raymond Chen
This is exactly how we think of memory in JavaScript. We don’t…
Indeed, since I stopped writing C++ code I forgot about memory management. And I couldn’t be bothered. Why would I? I mean it just works. Here’s a variable, here’s another one, no worries at all… Nowadays memory leak is rarely an issue. Most of the time you need to put an effort to create a one…
But it wouldn’t be JavaScript if there were no interesting quirks and features hidden behind this area…
Further, we’ll explore JavaScript memory architecture, main concepts and organization. And memory lifecycle, from allocation to release.
Also, we’ll look through some common memory leaks and how to avoid them.
Memory
In programming everything requires space. Number, string, object, function. Even in the abstract Computer Science algorithmic department, there’s a measurement for a space complexity.
Memory is different
In JavaScript (similarly to many other languages) there are two main types of memory Stack and Heap. Both are managed by the JavaScript Engine, both are for storing runtime data.
The difference lays in speed and size. Heap is bigger and slower, Stack is smaller and faster.
How does the engine know which one to use? The rule of thumbs is: if the engine is not sure about the size it uses Heap. If the engine can calculate the size beforehand, it uses Stack.
All the primitives like number, boolean, string, Symbol, BigInt, null and undefined always go to the Stack. Also, references are stored there, we’ll talk about references in a minute.
What’s left will end up in the Heap. This includes arbitrary objects and functions.
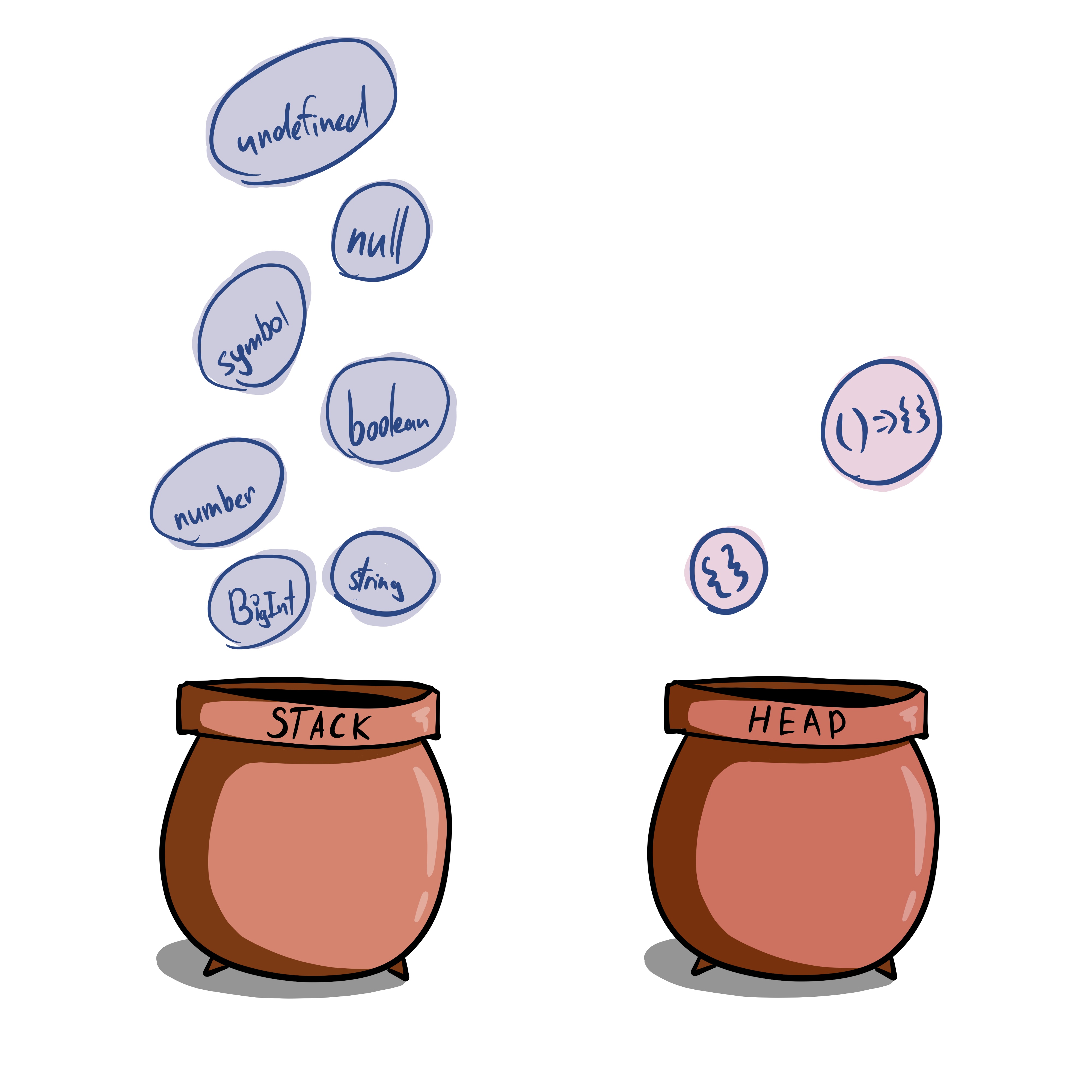
The data that goes in the Heap is usually called dynamic because it has unpredictable size (and potentially can change throughout the program execution) and is allocated dynamically at the runtime.
ℹ️ Have you heard of the term Hoisting?
Memory allocation in the Stack (aka static memory allocation) happening right before the code (next lexical scope) execution. References are stored in the Stack, thus they are allocated before the code is executed. Hence if we declare the variable it will be available even before the actual declaration in the code. Although value will be undefined because it doesn’t have value to point to yet…
|
|
Variables declared with let, var, const are hoisted, although let and const won’t return undefined.
References
The referencing concept is a major pillar of the JavaScript memory organization. It indirectly impacts how most of the key operations (such as assignment and equation) work.
However often it is poorly understood and thus results in occasional surprises and confusions.
Imagine a big bookshelf with multiple compartments. Each compartment has a label with a unique number on it. Every time you place something in the compartment you take a piece of paper and write down the number of the compartment and a short description of what is stored there.

This is the gist of how references work. The short description is a variable name, the shelf number is a memory address. The address is stored in the variable, which is stored in the Stack. And the actual object on the shelf is an object stored in the Heap, referenced by the variable…
Every time we use the assign (=) operator we are not assigning the value… We are creating a pointer to the memory where the value is stored. Your variable storing the address, that pointing to the memory where the actual value is stored.
Some personal opinion here…🤪
I think the language we use matters. Therefore I think the word “assign” and operator = is evil misleading and creates cognitive confusion and unnecessary simplification. I think a huge amount of bugs came from such confusion.
I’d personally prefer to be more explicit about what is happening and suggest using a term like “pointing” or “referencing” instead of “assigning” and operator like -> instead of =.
But we have what we have 🤷
Now that we have an idea of memory organization, let’s reinforce it with some examples. We will start with primitive values and gradually move toward objects…
|
|

As we figured before we are not setting value we are pointing to it… Pretty straightforward so far, let’s make it a bit more complicated…
|
|
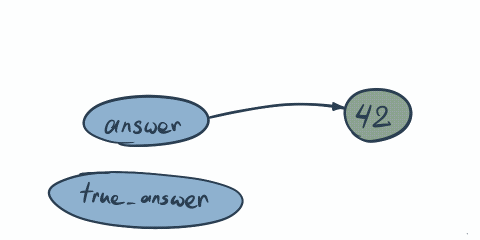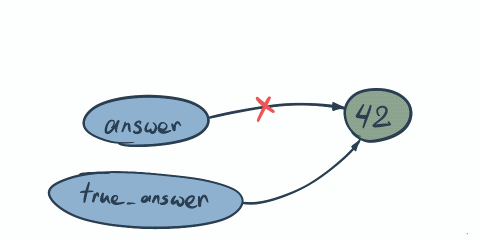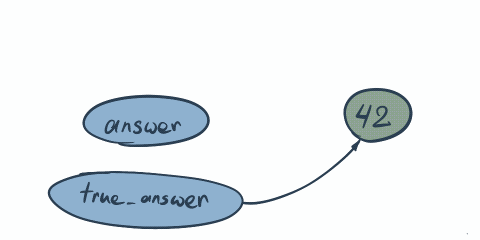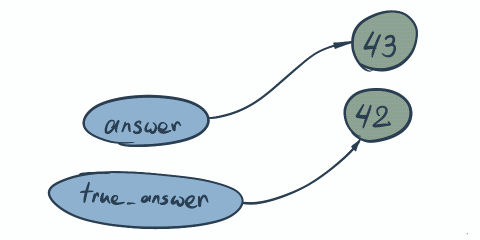
Same principle here. First both answer and trueAnswer point to the same address where value 42 is stored. Once we do answer = 43 we change not the value, but memory where we pointing…
Primitives are immutable. It kinda becomes obvious and almost redundant to mention if we talk it through. If we try to change 42 (e.g. add 1 to it), we will simply get another number, which is not 42…we won’t change 42 (42 will still exist)… Hence it is immutable.
Nor we can extend it. E.g. 42.value = 22 won’t work, although it will if 42 would be an object…
Hope it all made sense lol 😅
Let’s do another example with primitives… null and undefined are primitives. What does that mean? They act like all primitives…
|
|

Now we see why both values are strictly equal, pointing to the same value.
Funny fact
|
|
It is not true, null is not an object. It is a bug that can’t and won’t be fixed…
Let’s do the last one on primitives…
|
|
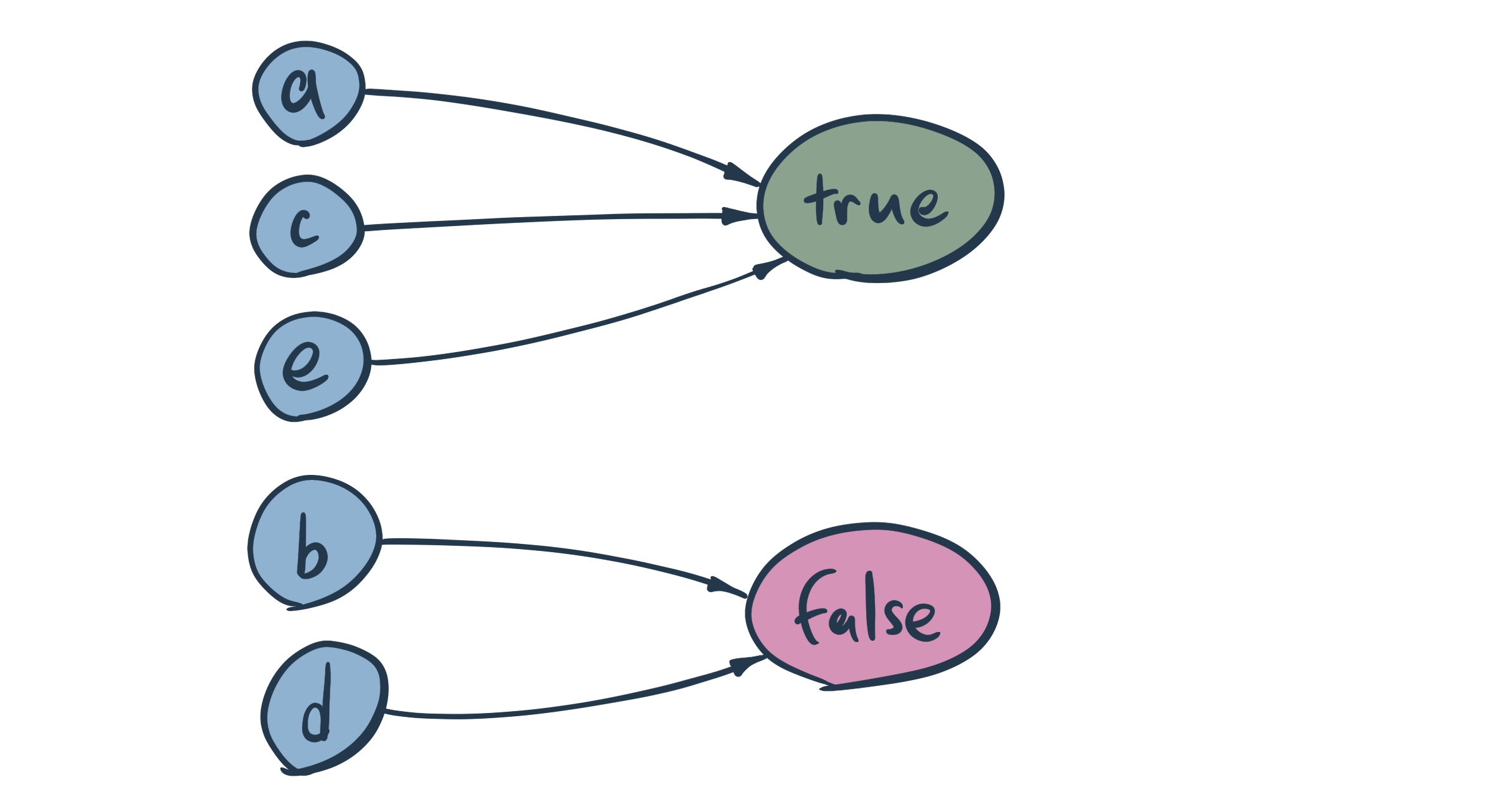
Everything looks very familiar.
Now let’s try something new. Objects. Objects are different, they represent a more complex tree-structure 🌳. And unlike primitives, objects are mutable. This property produces some interesting effects.
This is where the = operator will reveal its full evilness 😈.
|
|

Probably not what was intended…
Remember that the = actually points to the data. We are just routing pointers here.
Luckily we can fix it easily…
|
|
With a help of ... (spread operator) we managed to clone whatever catzilla was pointing to in the new address and made peanut point to it. This is not the original intention, how this operator should be used. But (as it usually happens with JavaScript) this side-effect was warmly accepted by the JavaScript community as a way to perform shallow cloning.
Things start to get really messy with more complicated objects…
|
|
It happened again… Both cats have the same color, although it wasn’t the intention…
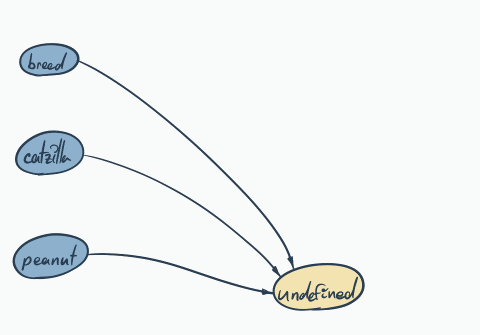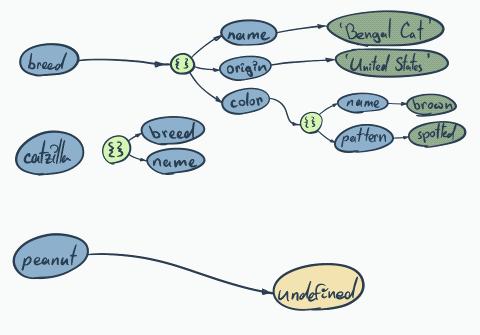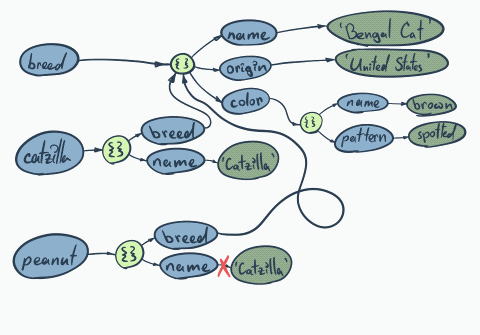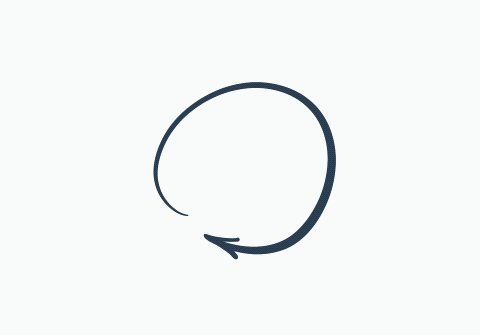
We are performing the so-called shallow clone only top layer (first level of the tree), to make it work properly we need to perform so-called deep cloning. The easiest way would be doing something like…
|
|
Ugly, but does the job. It forces the engine to allocate a new chunk of memory and fill it with object data.
Unfortunately, JavaScript does not provide a good cloning mechanism out of the box. Hence this is the approach to clone the object without employing extra tools.
If you are after a more elegant and efficient solution, I’d recommend using something like underscore.js.
Alright, here’s a curly one ⚾… Can you guess why this happening?
|
|
Surprised?
Let’s try to re-write this example a bit…
|
|
Does it make more sense?
== and the strictly equals === operators work, unfortunately, it is not very trivial. However, to prevent this article from bloating, let’s just say that comparison happening by actual value in the variable. As we know now it is an address of the object, rather than value. Because we are pointing to two different objects, located by two different addresses. Values are not equal…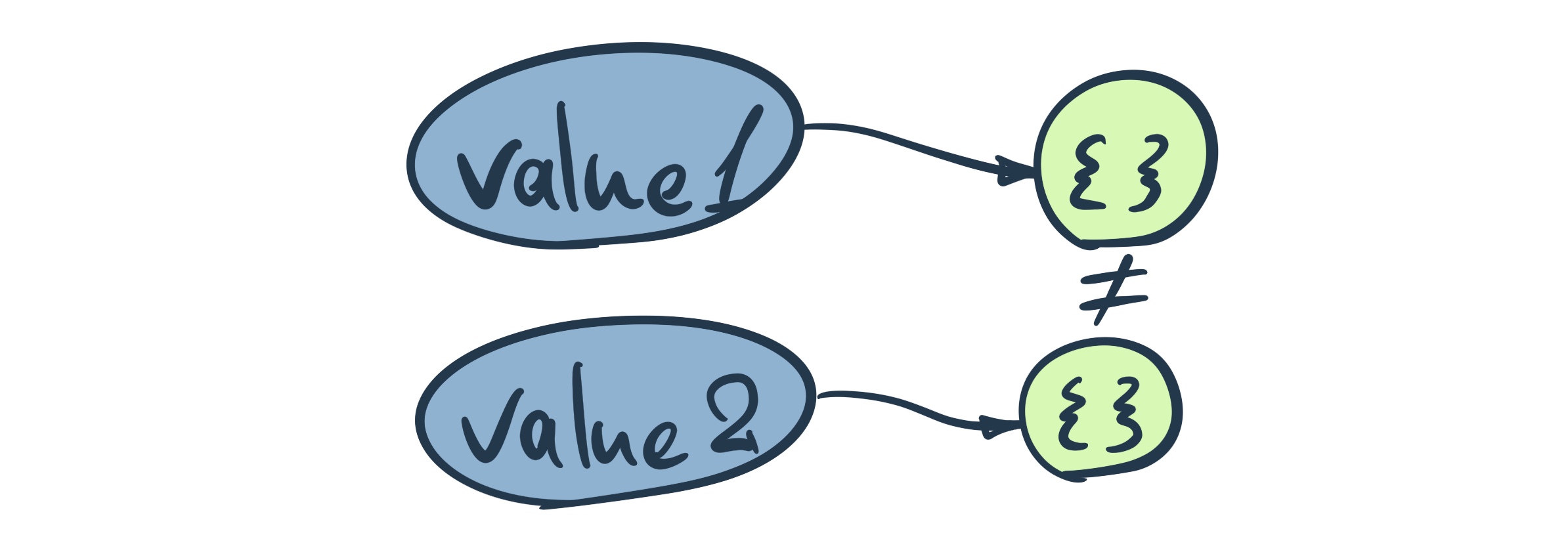
Garbage Collection
The concept of reference (which we just discussed) is what the process of memory releasing/cleaning (aka garbage collection) is based on. Using references garbage collector can determine what is “garbage” and requires a collection and what is not yet.
There are two main algorithms used for that matter.
The “new” one: its variation is used in all modern browsers
And “old” one: nowadays its variation is rarely used anywhere, because of its built-in flaws (we’ll talk about them further)
New: Mark And Sweep
Principle lays in finding unreachable objects…
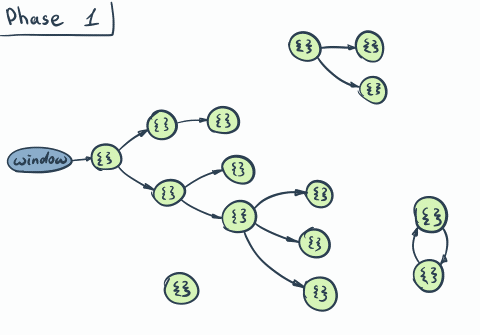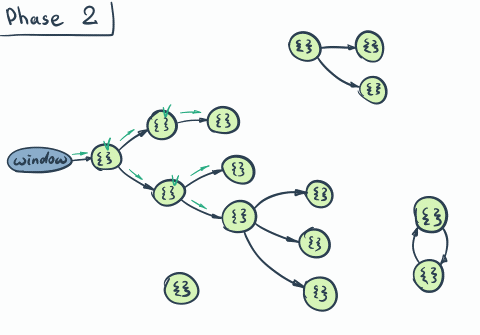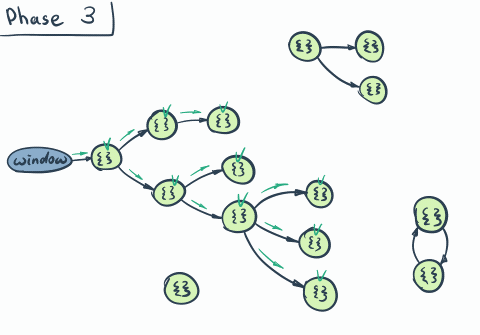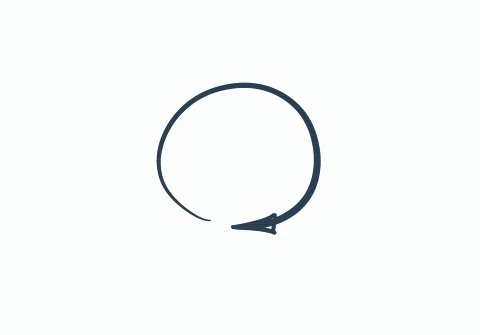
The unreachable object is any object that can’t be reached via traversal through references from the so-called root. In browser-world root is represented by the window object (aka Global Scope).
window object…Every now and then, garbage collector starts. And follows these phases
- Start phase: Once started, it assumes that all objects are unreachable.
- Mark phase: Then the actual tree traversal from the root (through references) starts. Every object found on the way is marked as reachable.
- Sweep phase: Once traversal is finished all unreachable objects are eliminated.
Optimization
Mark and Sweep algorithm belong to the Tracing Garbage Collection family. There are few family-dedicated optimizations (like tri-color marking). These are low-hanging fruits 🍐.
Nevertheless, most JavaScript Engines will perform some additional optimizations that are usually borrowed from other garbage-collected languages.
One such classic optimization is the so-called garbage collection based on generations.
The principle is based on one observation. Old objects are less likely to be garbage-collected. They proved it by surviving multiple garbage collections. Thus statistically we can assume these objects will be kept in use.
With this knowledge, we can improve the garbage collection time significantly by simply rarely bothering old objects 👴.
Here is how it works. Each object is assigned to a generation. All objects start at the zero generation. If an object survives garbage collection it moves up, to the next generation. The garbage collection is happening on the young generations more frequently than on old ones.
The more garbage collections object survive the older generation it is assigned to and the less likely it will be collected.
Ultimately this approach reduces traversals through statistically “low-chance-collection” candidates. And focus on those who statistically have higher chances to be collected…
Old: Reference Counting
This algorithm was last used in IE 7 and deprecated since 2012. So this section serves purely historical purposes.
Unlike the Mark and Sweep, this one will try to find unreferenced objects instead of unreachable…
This algorithm does not try to determine whether the object is still needed (in the previous example reachable from the root). Instead, it only checks if anything references the object.
This might not look like a big difference, but this approach is less restrictive. And due to this fact comes with a major flaw.
Major flaw
The major flaw is circular references. Two objects might not be reachable, but as long as they reference each other they won’t be collected.
Let’s look at the following example…
|
|
The above code (if used with the current algorithm) creates a memory leak. Because memory allocated for variables cat and dog will never be collected, even though it never used in outer scope…🐱🐶
Memory Leaks
🤔 Why do memory leaks still exist?
Because the process of determining whether a certain piece of memory is used or not is a so-called undecidable problem. Sounds scary, but it means that there’s no good way to program a machine to determine if memory can be safely released. Thus only a human can make a real complete judgment about it.
While we were exploring the old garbage collection algorithm we saw an example of a memory leak. It appears that a memory leak is just an accidentally forgotten reference to an object. An object that never going to be garbage-collected. And will keep uselessly occupy memory as long as the application is running. There are quite a few ways to create a memory leak.
Since we know how the memory is allocated and garbage-collected we can look through few most common examples
Global variables
Nowadays usage of global variables is a mauvais ton (bad practice). If happens, it is usually accidental. This problem can be easily caught by the linter 👮. Or prevented from happening by adding use strict at the beginning of the file.
The leak happens like this.
- We create a global variable (it is automatically referenced by
window). - And it forever stays there…
The Fix
Don’t use global variables.
It has been recognized as a bad practice for a reason. So the best way to avoid this problem is simply to avoid global variables.
Observers or Forgotten interval timers
This one is harder to trace, we forget to release timers once we don’t need them.
This leak happens like this.
- We create an interval timer with a callback like
setInterval(() => {}, 1000); - We make sure we referencing something from the outer scope
- The thing we reference will never be garbage-collected
|
|
The memoryLeak object will never be released even though we might not need the whole object anymore.
The Fix
The best way to prevent this from happening is
|
|
A Camouflaged version of the global variable or Detached DOM elements
Another classical one. If you are working with something like React or Angular, there’s no reason to worry. Nevertheless, it is an interesting way to lose some memory 🧠…
It is a camouflage version of the global variable memory leak. And it happens even nowadays pretty often, usually in-between the script tags.
This leak happens like this.
- We reference arbitrary DOM elements in the code (e.g. by calling
document.getElementById('i-will-leak')) - Even though we delete the element from the DOM it still hangs in the lexical scope or global scope (e.g. by calling
document.body.removeChild(document.getElementById('i-will-leak')))
|
|
The memoryLeak will never be garbage-collected, the removeChild here is very misleading, it seems like it will remove the element from everywhere, but it does it only for the DOM tree.
The Fix
The fix is the same as for the Global Variables leak. Don’t use global variables 😀 Instead, we can use child lexical scope, e.g. function
|
|
This is self-executable function will create a local lexical scope and after it will finish execution, all local variables will be garbage-collected.
P.S.
If you’ve read my previous JavaScript-Runtime-related articles, you know that JavaScript Runtime differs between browsers. Therefore the way memory is managed from browser to browser might be different. Although it would be unfair not to mention that in the past decade more and more commonalities appearing. And reduces a headache for us…
Moreover, given the unstoppably growing JavaScript infrastructure, including various linters, module bundlers, and well-matured frameworks for DOM interactions, problems with memory leaks are reduced to a bare minimum.
But…Garbage collection is still listed as an undecidable problem, hence there’s always a way to make a boo-boo. Understanding the way JavaScript organizes the memory and how references are managed might save you hours and hours of debugging.
Anyhow, hope you enjoyed the read and found something new for yourself 😀