And you are always welcome to buy me a coffee ☕.
In general clean architecture is a pretty bold statement. However, at the same time, it is a hollow and opaque thing to say.
How do you measure the cleanness of the architecture? By the number of components in the system? Nope… Whether it is cloud-first or not? 🤷. By the number of rectangles on the whiteboard? Probably not. Does your source code suppose to look good? It supposes to, but you know… Test coverage? Easiness of writing tests? Extensibility? Is 10-year-old clean architecture is still considered clean nowadays?
You will find million of clean architectures online. Whenever someone says “clean architecture” both my subconsciousness and google search pulling out the same thing. The book “Clean Architecture: A Craftsman’s Guide to Software Structure and Design” by Uncle Bob Martin. The main pillar, or to be more precise 5 pillars are S.O.L.I.D. principles. You can even find it on Wikipedia. I mean you know the thing is serious when you can find it there…
Once something gets popular it immediately starts the flame of rage. Like Linux vs Windows, Android vs iOS, C# vs Java, Angular vs React, you name it…
Well S.O.L.I.D is no exception. There are many people in opposition to ole’ Uncle Bob. One that (IMHO) outstands is Dan North. You might have heard of him as one of the originators of Behavior-Driven Development (aka BDD). This guy deserves some credit. Anyway, he came up with his own Clean Architecture principles CUPID.
What I’m saying here is that the principle acronym must form a catchy word! Oh and that any principle is not a silver bullet, even following SOLID principles you might end up with a big ball of mud. But there are a bunch of valuable guidances, following which might reduce the probability of 🦆ucking things up.
I think of Clean Architecture as a philosophy of some sort. It is not completely about the system today, but about the system today and tomorrow. It is not an arbitrary set of patterns, approaches, or coding technics. Clean Architecture is a product of system thinking that enables system evolution through continuous refactoring without ruining the integrity of the system (in any way you can think of it).
There is no such a thing as a complete code or finished software. There is abandoned or deprecated software. Everything else is a “work in progress”.
Unfortunately, we can’t forecast the future, but we can make sure that however, we decide to build the application today won’t bite us in the future. The design must be sustainable, robust for changes. It should be built with refactoring in mind.
Of course, a nice diagram is a must too 🙃
The Triangle 📐
So here we go, let’s start with the diagram…
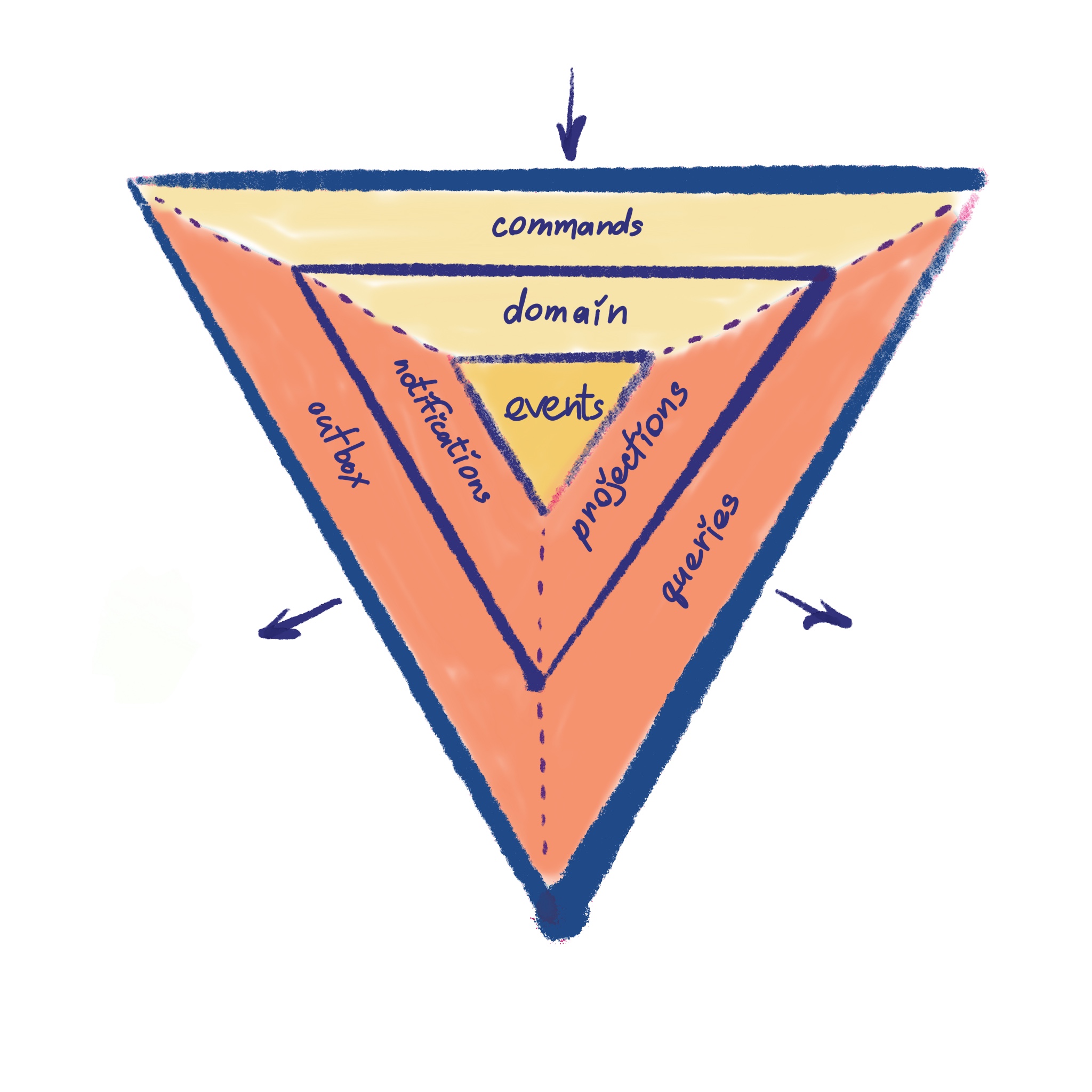
It is pretty much 3 triangles, one overlaying another forming three levels. All together it represents a visual representation of the architecture. We will go over all of the levels from the inside out.
Inspirations and ideas
At the high level, this architecture represents a mixture of hexagonal architecture (aka ports and adaptors) and its close buddy onion architecture.
Here are few things worth highlighting at the start
- Coupling. The coupling goes inwards and only one level deep. There should be no outward dependencies and hops or bypasses between triangles.
- Levels. Every triangle/level bounds together concepts that have a similar rate of change.
- Sides Sides are these named trapezoids. There are three sides on each level. Each side can communicate with its level neighbors.
- Direction. Every side has a strictly defined direction of data flow and communicational purpose.
At the first glance, all these concepts might feel a bit convoluted, but by the end of the article, they should make more sense. So without further ado, let’s begin.
Core Triangle. Level 1. Events. Storage.
In the heart of the architecture are events. It kinda makes sense, given we are talking about event-driven architecture 🙃.
This means that the source of truth for the system state is stored as event streams. In the… wait for it… event store. You might know this pattern as Event Sourcing.
The fundamental idea of Event Sourcing is that of ensuring every change to the state of an application is captured in an event object, and that these event objects are themselves stored in the sequence they were applied for the same lifetime as the application state itself.
– Martin Fowler, Event Sourcing
Event Sourcing is not new, it has been around for decades. I believe one of the reasons for its gaining popularity is that it fits really well in the Domain-Driven Design. In fact, one of the key elements of Domain-Driven Design is so-called Domain Events. Which will be a one-to-one map to what we will be stored in our “clean” Event Store. More on DDD coming further
These events are what we would call private events. Events that will never leave boundaries of this application. Or event level 2. Hence is the name private events.
Key takeaways
Events are a source of truth for the system. They are hidden from the outside and never leave application boundaries.
Middle Triangle. Level 2. The Logic.
This is the place where a lot of things will be going on. Business logic, data mapping, and exposure, and much more…
Domain
Let’s start with the Domain. I’m a Domain Driven Design evangelist. Thus here under Domain I imply what Eric Evans implies by Domain in the Blue Bible of Domain-Driven Design
Domain-Driven Design is an approach to software development that centers the development on programming a domain model that has a rich understanding of the processes and rules of a domain.
– “Domain Driven Design” Martin Fowler
The key thought is -> Without a well-crafted, religiously modeled domain, there’s no way we can produce clean architecture. That’s a given. We must understand, not guess, but understand what we are building. Which business problem we are solving. DDD is a great tool for that.
There’s a bit of color-coding going on on the diagram. If you look closely, you can see that domain and commands are in different colors. The color indicates the direction of the data flow in the system. The domain belongs to the writing layer.
Domain encapsulates all invariants and emits events. The role of the Domain is to validate whether the system in its current state can satisfy the incoming request (aka command) or not.
Notifications ✉️
Notifications aka public events. These are events that are often constructed from private events. Their only responsibility is to notify the outside world that something important has happened. These events are used nowhere internally, they always go outside. Think of public events as public APIs. Hence the name public events.
Events might be as lean as
|
|
This event basically notifies the outside world about the fact that the user has been added and provides a piece of minimal viable information for anyone to go and pull any extra required information.
Or an event might be beefier like
|
|
This event transmits everything the system knows about the new user.
Which one to use is dependent on how generic and re-usable your public event should be. Do you want to serve extra information on-demand or broadcast all the changes once they occur?
Projections
Projections or projected views serve purely read purposes. They usually represent a denormalized representation of the data stored in the event store. Denormalization of the data is necessary to tune its shape to a specific query. Therefore provide a cheap and easy way to query the information.
It is a great way to serve general-purpose queries, e.g. “give me a list of all users in the system”. Another way of looking at it is as a long-living cache.
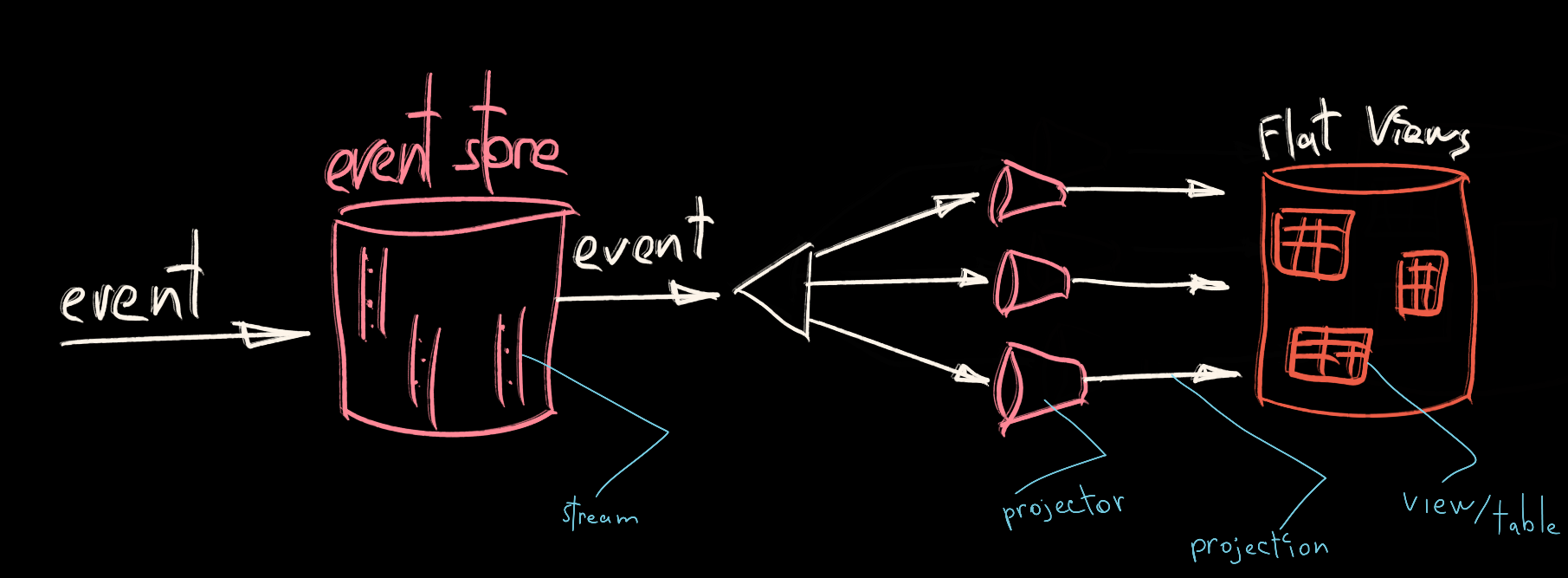
Projections are filled during the application runtime. Usually, it depends on whether data have to be strongly consistent or not, the projection process will be either synchronous or asynchronous.
Key takeaways
The only way to mutate the system state is through the Domain. A well-crafted Domain is crucial. The domain is responsible for validation and events emission.
Notifications are public events that are targeted outside of the application boundary, keeping external systems up to date with important updates.
Projections are denormalized views of the event store. Projections are filled by projecting private events during the runtime. Data is always shaped in the most comfortable way for query execution.
Outer Triangle. Level 3. The Exterior.
The outer layer is exposed to the outside world and defines communication contracts. Disregard any particular technology or communication protocol. We are all about abstractions and fancy diagrams here :D
We’ll start with a traditional CQRS, that will cover two corresponding sides of the triangle. I’m sure you guessed, but anyway 🥁… commands and queries.
Commands
The only way to mutate the system state is by issuing a command. If the client wants to perform an action that supposes to end up with a state update, it has to go through the commanding part of the layer. A command is an intention, not a fact. It might be rejected as well as accepted. If the Domain from Level 2 says “no” to a command it is marked as rejected.
Queries
On the other hand, if the client wants to read the state, the inquiry has to go through the querying part of the triangle. The query must ask a well-defined, expected question. The projections (from Level 2) will provide well-formatted sufficient data, that will be propagated all the way to the client.
Outbox 📤
Last, but not least is the Outbox. It consumes so-called public events (aka notifications) and ensures they are dispatched outside with an “at least once” delivery guarantee and respecting the order. This is the main channel for public events to get outside.
The concept of public events and outbox eliminates the boundary trap.
Key takeaways
This level defines clean mechanisms for communication with the system. There’s only a single way to impact the system state, through Commands. There’s the only way to read state, through Queries. And finally, there’s the only way to subscribe to the latest updates from the system, through the Outbox.
Bottom Line
That’s how I envision clean event-driven architecture. Each moving part has a well-defined responsibility and direction of data flow. And this way each part can evolve, scale, be replaced, or re-factored independently.

Hope it all makes sense, let me know if it doesn’t.
Keen to hear your thoughts and arguments 🧠 💭