And you are always welcome to buy me a coffee ☕.
Before we begin
There are few things worth noting before we kick things off…
First thing
Let’s clarify what do we mean by the term Event Sourcing. Event Sourcing is an approach for storing and restoring system state in/from a series of strictly ordered events, grouped into streams.. Ultimately it is a way of communication with the database or wherever events are stored.
The fundamental idea of Event Sourcing is that of ensuring every change to the state of an application is captured in an event object, and that these event objects are themselves stored in the sequence they were applied for the same lifetime as the application state itself.
– Martin Fowler, Event Sourcing
Anyhow all the definitions above miss one important aspect. Events are not arbitrary blobs of data or objects. Each event has a name (or we can call it a type) that captures its meaning for the system and often some extra data to enrich the cognitive value of itself.
Another way of looking at events is as a contract. In Event Sourcing, it is a contract between something that uses events and something that stores events. Let’s keep it in mind for later.
Second thing
Few more terms that often have a vague meaning. Sometimes event versioning and event migration are used as synonyms or substitutional terms to define the actual process of event evolution. However, it is two separate, although dependent problems that need to be tackled independently. Thus I emphasize attention on segregation, versioning goes left, migration goes right.
Third thing
You probably heard of it. Event Store is immutable. And it is not completely true. Hold your tomatoes 🍅 for a minute. I’ll try to explain what I mean, without going too far in-depth…
The data in the Event Store is immutable or should be treated as immutable only from the business perspective. In other words, during the routine application work, the only allowed actions are new stream creation and new event emission. And any sort of reading actions.
In the end, we will have the original balance and two events, one compensating another.
Out of routine application work, there are a lot of reasons to merge, split, update, remove streams of events, events, or even event data.
The most common reason is optimization. If the data in the Event Store becomes a historical artifact that does not tell anything about the current state of the system and won’t be used for audit purposes, archive it and eventually hard delete it. It is just useless.
The Evolution
Evolution is change in the heritable characteristics of biological populations over successive generations. These characteristics are the expressions of genes that are passed on from parent to offspring during reproduction.
– Wikipedia
Let’s talk about evolution in the context of Event Sourcing. There is no such thing as a finished application. Systems do evolve with time. Most of the time it is either business requirements evolution or bugs that stimulate this process. Both of these occasions don’t require an extra introduction. However, they will unavoidably impact events.

There are two ways how event can evolve:
- the event might become a new version of itself
- or become a new event (or set of new events).
What determines the direction of the change? When does an event evolve into a new version and when it evolves into a new event?
The event will evolve into a new incarnation (version) of itself when evolved requirement does not change the event’s meaning, but rather schema. Hence a new version of an event must be convertible from the original one (old version). Therefore the name/type, which represents the essence of the event must not change.
If an event’s meaning changed and one-to-one conversion is impossible, that’s a sign to introduce a new event (or events) that carries new meaning.
A new version of an event must be convertible from the old version of the event. If not, it is not a new version of the event but rather a new event.
– “Versioning in an Event Sourced System” Greg Young
We can use this as a rule of thumb: if you are struggling with a conversion of the old version of an event into a new one, most likely you are dealing with the new event, not with a new version.
Let’s look at the example below.
Imagine there’s a comment system where users can delete comments. Every time user deletes a comment new event is emitted
|
|
Time passed and new requirement arrives. “All users must specify the reason for the deletion”. Sounds reasonable, so from now on the event should look as follows…
|
|
This is a simple example of event evolution forced by requirement change. The meaning of the event did not change. However, the payload did.
The Breaking Change
We mentioned that event also represents a contract. The contract between the event store and the system/application.
If we look at events through this lense the biggest driver to introduce a new version would be a breaking change in the existing event schema. A breaking change is any non-backward compatible change. In other words, something will break if we change the event’s schema this way. We’ll get back to this topic in more detail later.
In real life, events do not always evolve from one version to another by expansion. Sometimes they shrink.
When a new version of an event loses some of the payload without gaining, it is not a breaking change. Hence we don’t really need a new version of an event, we can just ignore the data that we don’t need.
I use the following table as a decision navigator.
| Scenario | Action | Do we need a new version? |
|---|---|---|
| all data exists on the old version and required in the new version | should be copied | no |
| data exists on the old version, but not all of it required in the new version | ignore obsolete data | no |
| a new version has some new fields, but they are nullable | set null | no |
| a new version has some new fields, but they are not nullable | conversion required | yes |
| data exists on the old version and on the new, but the schema of data changed (e.g. type changed or field name) | conversion required | yes |
Long story short. Unless it is a breaking change, there’s no necessity for a new version of the event. Unless you want to capture all schema permutations.
Where’s the catch? 🎣
With the new event, it is pretty straightforward. Follow the regular routine, how you’d introduce a new event on any other occasion.
With the new version, it is a bit more tricky. Once you introduced a new version, now you have two events that carry different data but have the same meaning. Moreover you probably already accumulated some old events in your event store. Looks ambiguous, isn’t it?
The original reason behind the introduction of a new version of the event is a new/evolved requirement (or bug). The same reason makes the old version of the event obsolete.
What does it mean from the system perspective? The system should only see a single version of the event, the latest one.
From now on, the new event version is the only legit representation. Any old version should be simply invisible. It’s like it never existed before.
Getting back to one of our initial claims: the event store is immutable. And it is not a problem when we introduce a new event or deprecate an old event. But what should happen when we introduce a new version of the event?
Let’s try to visualize what we’ve just said.
Imagine there’s an event stream. Where different color represents different events. It has been going on from 2:00 o’clock. Somewhere between 3:00 and 4:00 we introduced a new version of the light blueish event (v2).
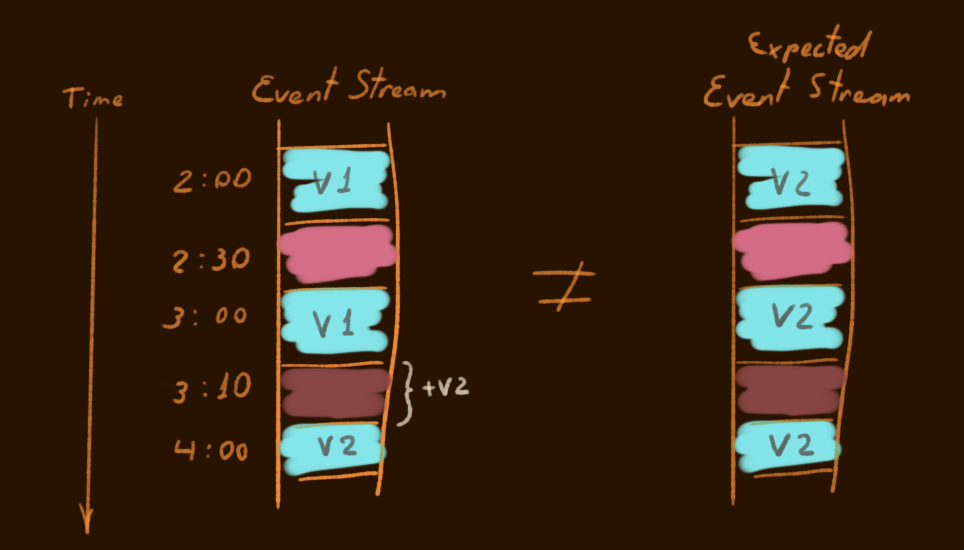
On the left is reality, what we will end up within the Event Store. On the right is what our system should expect. Notice the difference? On the right-side, all events are of the latest version.
Distillation
Event evolution is a natural process of any active event-sourced application.
The event might evolve into a new version of itself or into a new event. You can determine the direction by validating whether you can easily convert an old event into a new one. If you do, you are dealing with a new version, if not a new event…
The main driver behind the event’s version-to-version evolution is a breaking change in the event’s payload schema. Use a table from the above to determine whether you are dealing with the one.
Last, but not least, the system must “see” only a single version of the event, the latest one.
Further down we will focus on the version-to-version evolution and possible ways of dealing with it.
Event Versioning
First and foremost let’s find a good data structure to describe the event version, given what we know so far about it.
Let’s go over key aspects of versioning.
- old version must be convertible to the new one;
- we don’t have any limits on the number of versions, our system might well have any arbitrary number of versions for any particular event;
- given our system “forgets” about old versions we can only operate with the current version and future version (the one we are introducing) at any given point in time;
What if we will represent every version of an event as a node. And the ability to convert the old version into the new one as a directional connection. Boom and we are getting a Linked List.
Let’s try to visualize it really quick.
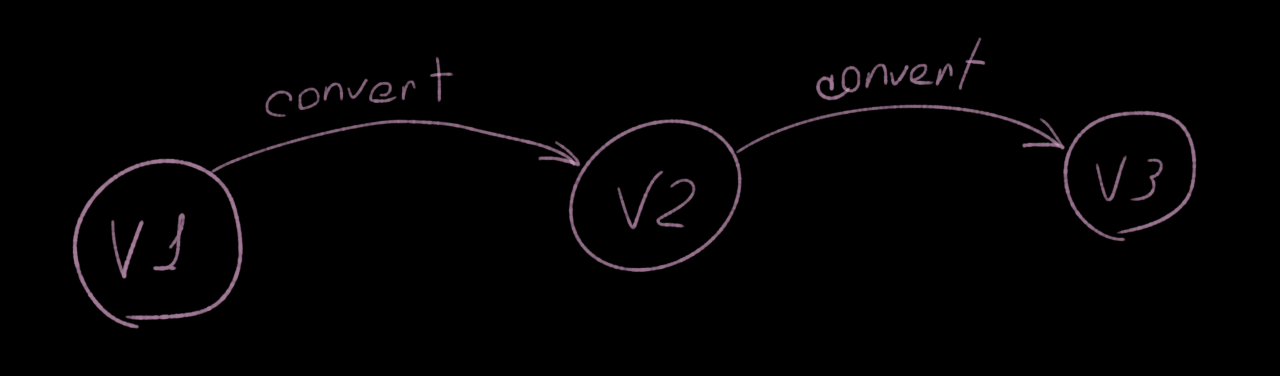
Looks very nice and elegant. Responsibility boundaries are well defined. Any given version will know how to convert itself to the next one and only the next one. And the tail will always represent the latest version. The one that our system is actually interested in.
Conversion/Migration
Given we came up with a linked list to describe the relationship between versions, the conversion from any given version to the next one and ultimately to the latest becomes very trivial. All we need is traversal from the current version to the tail. And tail will always be the last available version.
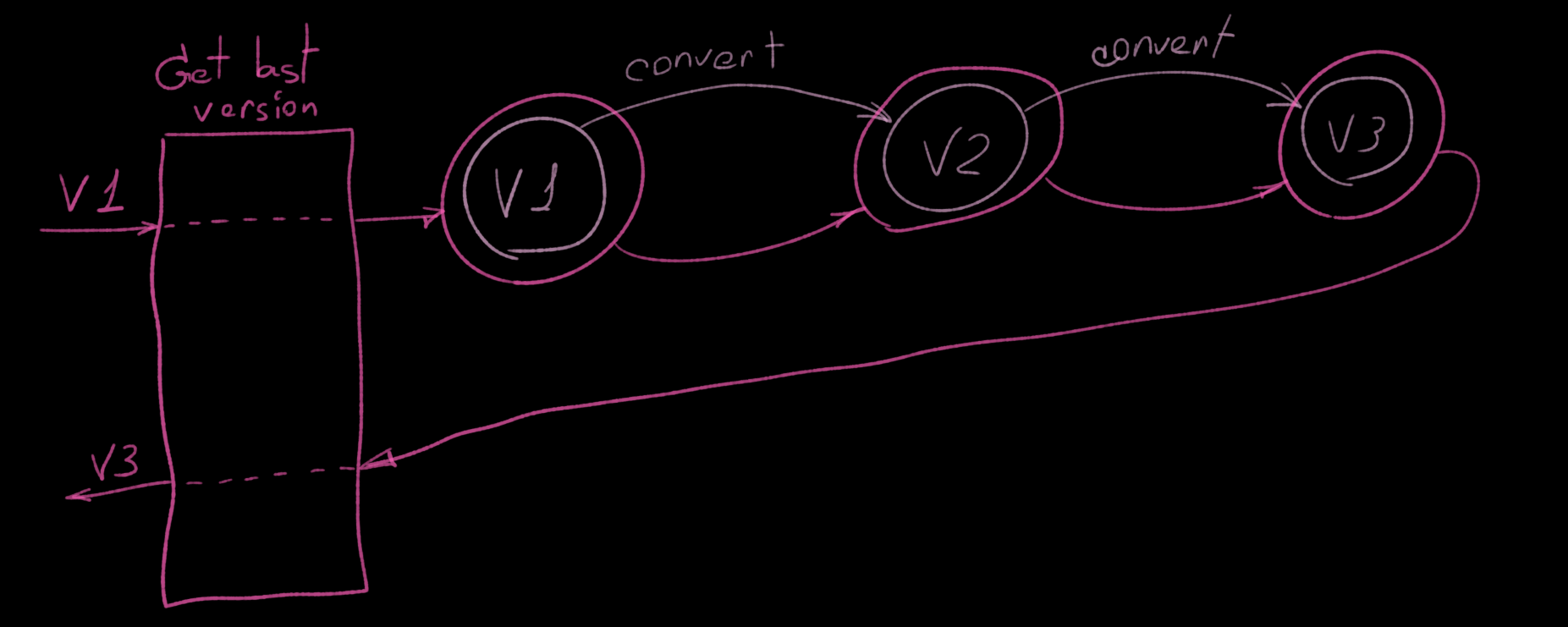
When?
Seems like we have a good way forward. We have a way to define a version, we have a good understanding of how to get from any given version to the last one. So when should we do it? And the answer is “it depends…”
It depends on whether you can afford to have a down-time, on the average active lifetime of arbitrary stream in your system, and your snapshotting strategy.
I have only my own experience at my disposal so I’ll use it to define the median case.
In-store migration
This is when you update data in the event store itself. I don’t like this approach as it kinda violates the integrity of the data. You are mutating the Holy Grail of the Event Sourcing… Events.
Additionally performing something like blue-green deployment or canary deployment without downtime is possible, but might appear painful :). Keep in mind you will have to compensate accumulated delta between releases.
Out of the store migration
More common and in my opinion more reasonable way of dealing with it is covert on demand. This means we will leave the event store untouched, instead, our state reconstitution process will be responsible for event conversion.
Let’s get look at the reality vs. expectation example, but now with conversion in-between.
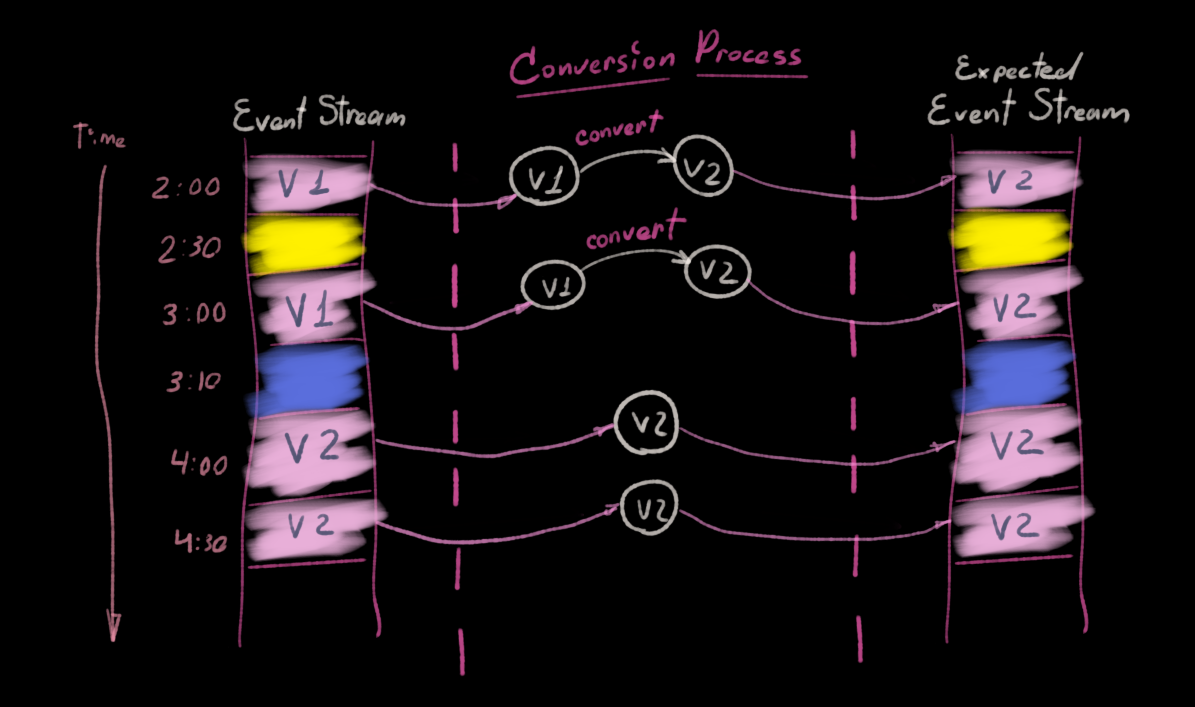
It is particularly useful when the active stream lifetime is not very long and you know that ultimately every stream will be either archived or serve only for audit purposes. It means that eventually your Event Store will be constituted of streams with predominantly new versions of events. And those with old events will get less and less usage.
On the other hand, if your streams have a fairly long active lifetime you probably will employ snapshotting strategy at some point in time. This will reduce the usage of old events as they will be processed during snapshot construction. However, it will require us to re-build the snapshot whenever we introduce a new version of the event as it will impact the snapshot.
Bottom Line _______
Applications evolve and unavoidably impact the shape of the data in the data storage. If you are using event sourcing, it means your shape of events will be evolving making some events in the event store stale.
Generally speaking, an event has two main responsibility:
- signalize about a change that has happened
- and carry information to enrich the value of the signal
If evolution changes what the event should signalize about it is a new event, if it changes underlying payload schema it is a new version of the event.
Event versioning is nicely fitted into the Linked List data structure.
The system uses only the latest versions of events. And to facilitate it we have two ways of dealing with old events. The in-store and out-of-store migration/conversion. I’m personally in favor of the last one, but presumably, there might be better cases for the first one.
Keep in mind that there are other strategies for dealing with event versioning, such as double push, etc. I think they are rather more applicable to asynchronous services than to event-sourced systems. But don’t take my word for it, there’s no silver bullet in the software engineering ;)