It has been a while since the word event became a buzzword in the tech community. And ultimately turned into an obfuscated term. It is used in a mixture of technical contexts which often overlap and create a whole new level of confusion. Check this out, there are Event Stores, event streams, event buses, domain events, and so forth and so on. Moreover, you’ll find events in the heart of different modeling technics (e.g. event modeling and event storming).
In all these contexts event might or might not be the same thing. And it is up to us to decide, but the decision comes with some consequences. We will try to remove ambiguity from the term, reduce boundaries opaqueness, and in the end we will discuss the consequences I mentioned above.
Here’s a quick agenda… First, we’ll define the meaning and distinguishable properties of events and what they share disregard where they are used. We’ll go over some of the major event application areas and focus on the differences between them. Finally, we’ll talk about boundaries between those areas. And how easy it is to create an event-driven ball of mud.
Events ⊆ Messages
Let’s first figure out where the term event takes its roots and what all events have in common.
Messages 📨
Message is a generic term for an independent, data blob usually with some meta-data attached to it, sent from the sender to the receiver. Think of messages on your mobile phone or emails in your inbox. Messages tend to have fixed pre-defined schema for the payload and meta-data it is carrying. However, the message payload is not mandatory and might be empty, which makes a message simply a signal. Message Name (or/and any other meta-data) is what helps the receiver to distinguish one message from another and adjust the expectation on how data inside will look and what to do with it.
ℹ️ Let’s stop here for a second and destroy one of the myths around messages.
To do that we need to get back to the mobile messengers ✉️📲. Why are they so popular? Don’t you think they had to die a long time ago together with ICQ (if you old enough to remember it 👴)? Appears message-based communication has a very strong advantage against any other type of communication. Asynchronicity. It does not require you to respond or take any action immediately.
You know when you ask a question, you see someone read it ✔, but they don’t respond 😡. Asynchronicity…
The myth is that messages by their nature bring asynchronicity in communication. That’s not true, messages don’t guaranty asynchronicity… The communication topology (dispatching mechanism) is what guarantees it.
Events

All events are messages, but the opposite is not necessarily true. Hence events are a subset of messages and do inherit all major message properties. Similarly to messages events have two major responsibilities, signalize the receiver (we usually call receiving system: consumer) and together with the signal carry information to enrich the signal if necessary.
The Name
One of major distinguishing characteristic for events is that they happened. Event is a fact that happened in the sending system (we usually call the sending system: emitter). Thus event names are always in the past tense. This claim implies and emphasizes that you can’t change an event or influence it in any way if it has already happened (unless you can travel in time). All you can do as a consumer is either receive and consume it or not.
Destination unknown
Events don’t have a destination. Another important factor is that the emitter does not know who is going to consume events if ever would. Events are just emitted… and thereafter the dispatcher delivers events to all consumers. It is the consumer’s responsibility to let the dispatcher know its interest in certain events. There might be a single consumer, multiple or none, it doesn’t matter from the emitter perspective.
Dispatching
So far we went through major shared characteristics of events. We figured that events themselves don’t guarantee asynchronicity, they are immutable and don’t have a final address. Further properties are defined by both the dispatching mechanism and application areas. Let’s go over some of the most popular ones…
Database
The first application area we’ll look at is a database.
The fundamental idea of Event Sourcing is that of ensuring every change to the state of an application is captured in an event object, and that these event objects are themselves stored in the sequence they were applied for the same lifetime as the application state itself.
– Martin Fowler, Event Sourcing
The principle
Instead of saving the current state of the system in a bunch of tables or documents, save everything that happens in the system in a series of events. The approach is known as Event Sourcing and the place to store events is known as an Event Store.
Event Store is not necessarily a separate database (while it might be), it well maybe just a separate table in your database. Event Store acts as a source of truth for the system state.
One of the biggest advantages of Event Sourcing against e.g. the relational database is that at any given point in time we can answer not only the question “What is the current system state?”, but also “How did we get there?”, which is pretty valuable if you ever tried to fix production bugs 🐞..
Think of “Hansel and Gretel” 👦👧 by Brothers Grimm. Hansel takes a slice of bread and leaves a trail of bread crumbs for them to follow home. Why does he leave them? Because he needs to know how did he get to where he is now.
Your application probably has 100 x n ways to get from arbitrary state A to arbitrary state B. Wouldn’t it be helpful to know which exact route brought the system to the current state?
💭 I use the word system a lot, but in the context of this article, it is interchangeable to domain or application, or service…
A system is a group of interacting or interrelated elements that act according to a set of rules to form a unified whole. A system, surrounded and influenced by its environment, is described by its boundaries, structure and purpose and expressed in its functioning.
– Wikipedia
Usually, Event Sourcing implies the usage of the Command Query Responsibility Segregation (CQRS) pattern. It would be challenging to use Event Sourcing without CQRS, so usually if there’s an Event Sourcing in use, CQRS is a given.
🔍 If we zoom out for a second and think of data storage in general…
We’d be able to claim that data storage is (most of the time) used to obviously store and occasionally access the data. The ratio between reads and writes heavily dependent on the problematic domain and always varies. Not even from application to application, but from time to time in a single application. And since the ratio is changing, at certain times either reads or writes start dominating and become a bottleneck. However, Event Sourcing has conceptual built-in segregation between “read” and “write”. Thus both read parts and write parts can scale independently…
Writes 🖊️
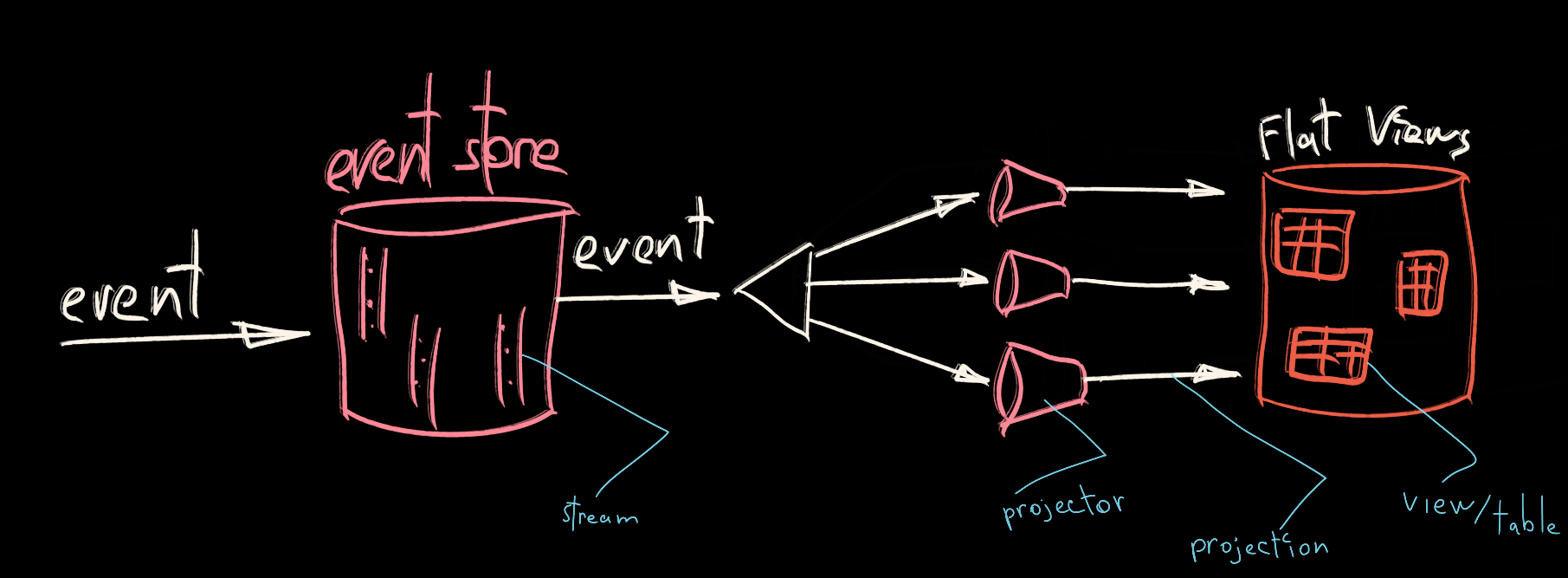
As you can guess by now, all “writes” are done through saving events in the Event Store. Since the Event Store is a source of truth for the whole system, all validations must be done against the replayed state from the Event Store. Worth mentioning another key element of event sourcing- event streams. An event stream is a special name for a group of events that have happened to a single whole. Events belong to the stream. Events in the stream are ordered strictly by time. Similarly, how your Facebook profile represents a series of events that happened to you since your birthday, an event stream represents a series of events that have been happening to some business entity.
Reads 👓
 Now “reads” have technically nothing to do with the Event Store itself, but more with the dispatching framework that is in charge. You see, we usually don’t read directly from the Event Store to show the data to the user. User data is usually stored in independent “flat” views or projections of events. Similarly how the GitHub projects a series of commits in the Pull Request file view as a final view of all your changes applied to files. Projections show the final/desired look based on the events in the Event Store. It is a common practice to keep your projections/view data in a denormalized shape, tuned for a specific output.
Now “reads” have technically nothing to do with the Event Store itself, but more with the dispatching framework that is in charge. You see, we usually don’t read directly from the Event Store to show the data to the user. User data is usually stored in independent “flat” views or projections of events. Similarly how the GitHub projects a series of commits in the Pull Request file view as a final view of all your changes applied to files. Projections show the final/desired look based on the events in the Event Store. It is a common practice to keep your projections/view data in a denormalized shape, tuned for a specific output.
The projecting process is usually not happening inline, but asynchronously in the background process(daemon 👿), moving your system from strongly consistent to eventually consistent. It is a fair expectation to have from the event sourcing framework to facilitate emission, distribution, and dispatching of events to special objects that will build desired projections. These objects are usually called projectors.
Asynchronous services
The second application area is service communication, to be more precise asynchronous service communication.
There are only two hard problems in distributed systems: 2. Exactly-once delivery 1. Guaranteed order of messages 2. Exactly-once delivery
— Mathias Verraes (@mathiasverraes) August 14, 2015
You can construct your event bus leveraging message brokers. Major cloud providers have either dedicated event bus as a service or queueing and messaging services that you can employ to build your bus in the cloud. Of course, there are some message brokers on the market that are dedicated to this purpose.
Asynchronicity

Nowadays McDonald’s still has counters opened for service. The experience might be pretty frustrating though, especially during lunchtime. First, you have to wait in the queue, make an order and wait again while the staff will get your order ready 🍔.
At the same time, everyone behind you is just waiting for your order completion. Funny enough the kitchen might not be even 50% busy. Of course, we can increase the number of counters. But fortunately, there’s another way to look at this problem. Terminals.
The queues at the terminals move heaps faster. The major reason is that after you complete your order, you don’t wait for it at the terminal blocking rest of the queue. Instead, you receive an order number, you can take a seat and use the number to validate whether your order is ready or not.
The first example with counters illustrates blocking synchronous environment. While the second example demonstrates an asynchronous approach where every actor in the process performs the task independently. And since the order collection increases the pace, the bottleneck moves from the order collection to the kitchen. What that essentially means is that your order is now dependent on the kitchen performance rather than on the number of counters, which kinda makes sense, isn’t it?
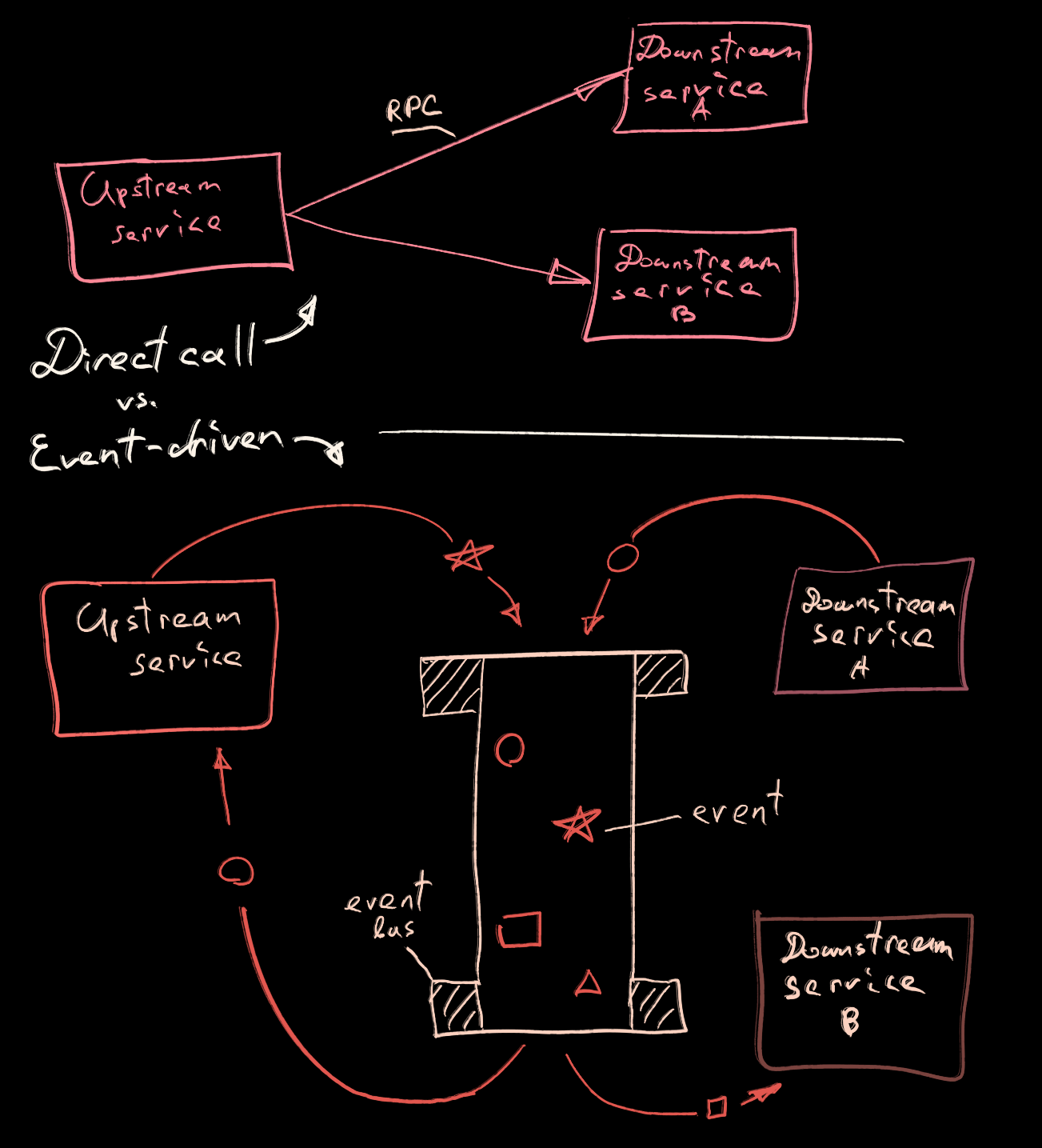
With an event-driven approach to services communication we can perform the same trick, but with downstream services. Our upstream service no longer needs to wait for downstream services to finish execution before proceeding. The upstream service just emits an event and that is where the responsibility of the upstream service ends.
Further, the dispatcher (event bus) picks up the message and delivers it to all subscribed services.
Dependency Inversion
Together with asynchronicity services become loosely coupled. This is something that will improve services boundaries hence integrity.
Let’s get back to our imaginary upstream service for a minute. It does not need to be aware of downstream services that depend on it. We simply flip the “who knows what” in the right way.
Your upstream might produce event feeds with a help of Atom or any similar web feed technology. Downstream services will have to do polling and check for updates and if something changed, pull new events from the feed and remember the last read update.
Imagine a car insurance application. Usually, your insurance policy depends on where you live. Hence when you change an address, the insurance policy changes as well. You can imagine there might be a billion extra things that need to happen after that… a new insurance statement must be generated, a monthly premium has to be re-calculated, five hundred notifications need to be sent, and so forth, and so on…
Now let’s dig a bit deeper and imagine that we have a separate service for every such action. We have an address service, which UI can leverage to change an address. The payment service, the statement service, the email notification service, who knows what else? the fax service 📠? etc.
Now the question is, does our address service need to know about all this stuff? Do we need to wait for all these processes to finish before releasing UI and allowing a user to move on?
The question is of course rhetorical. The only thing that the address service needs to do is validate and change an address and finally emit an event “The address has been changed to this and that”. That’s it. Rest is on other services to process that event and of course on an event bus to dispatch properly.
Streaming
I like to refer to event streaming as to a more intense variation of event-driven architecture, EDA on steroids if you will. In general, it has nothing that we have not discussed yet. An event is still an event, it has all quirks and features we discussed before, events still have to be delivered in a strict order to all consumers. The standing-out characteristic is that every next delivered event decreases the value of the previous event. It happens due to shifted priorities. Delivery and processing time gains priority over pretty much everything else- over the lifetime of an event, its value after delivery, occasionally even over consistency in delivery (yup, sometimes it is acceptable to lose an event or two).
 Think of the map where you can track your Uber Eats courier after you submit an order. As long as you know where your food is now, at this very moment, you don’t care where it was a second ago, even less you care where it was a minute ago, but you want those updates to keep coming and be accurate. Moreover, after your food has been delivered, you probably don’t care about any of that data anymore at all.
Think of the map where you can track your Uber Eats courier after you submit an order. As long as you know where your food is now, at this very moment, you don’t care where it was a second ago, even less you care where it was a minute ago, but you want those updates to keep coming and be accurate. Moreover, after your food has been delivered, you probably don’t care about any of that data anymore at all.
Thus event streaming and event stream processing are technics I’d use when strong consistency is not an option, hence we need to leverage events to provide a constant data flow and keep processing incoming data as soon as possible, bringing the eventuality to a bare minimum. You might meet it by different names “real-time processing”, “complex event processing”, “event stream processing”.
Boundary trap ⚠️
There’s a trap…
It is right in between the event-sourced service and the outside world. Imagine that we have a service that represents a single whole and it uses event sourcing. Now let’s add a few more services and finally an event bus between them. Do you see where I’m going?
It is very tempting to broadcast your internal service events out to all other services through the event bus. And it might be a good idea, butt 🍑… often it is not.
Public and Private events
As the first rule of the fight club says “A class should have only one reason to change”. You might know it as a Single Responsibility Principle (SRP).
Sharing your database entities is usually considered a boo-boo approach. And we can find tones of articles explaining why. Well, most of the arguments are still valid, and bringing events onboard does not change this fact much.
The event represents a contract. A contract between emitting system and consuming system. Hopefully, most systems do evolve with time. And if they do unavoidably the contracts will follow. In other words, we will be changing events every now and then. That’s a given. Once that will start to happen, we will start using words like “breaking changes”, “backward compatibility”, “versioning” much more often.
If we want to share something, we better design and build it for that purpose (in this case sharing 🤓). By doing so, any internal change won’t end up in potentially contract-breaking change. And vice versa if your consumers need the contract to change, you can do it without changing your database. Sounds obvious, huh?
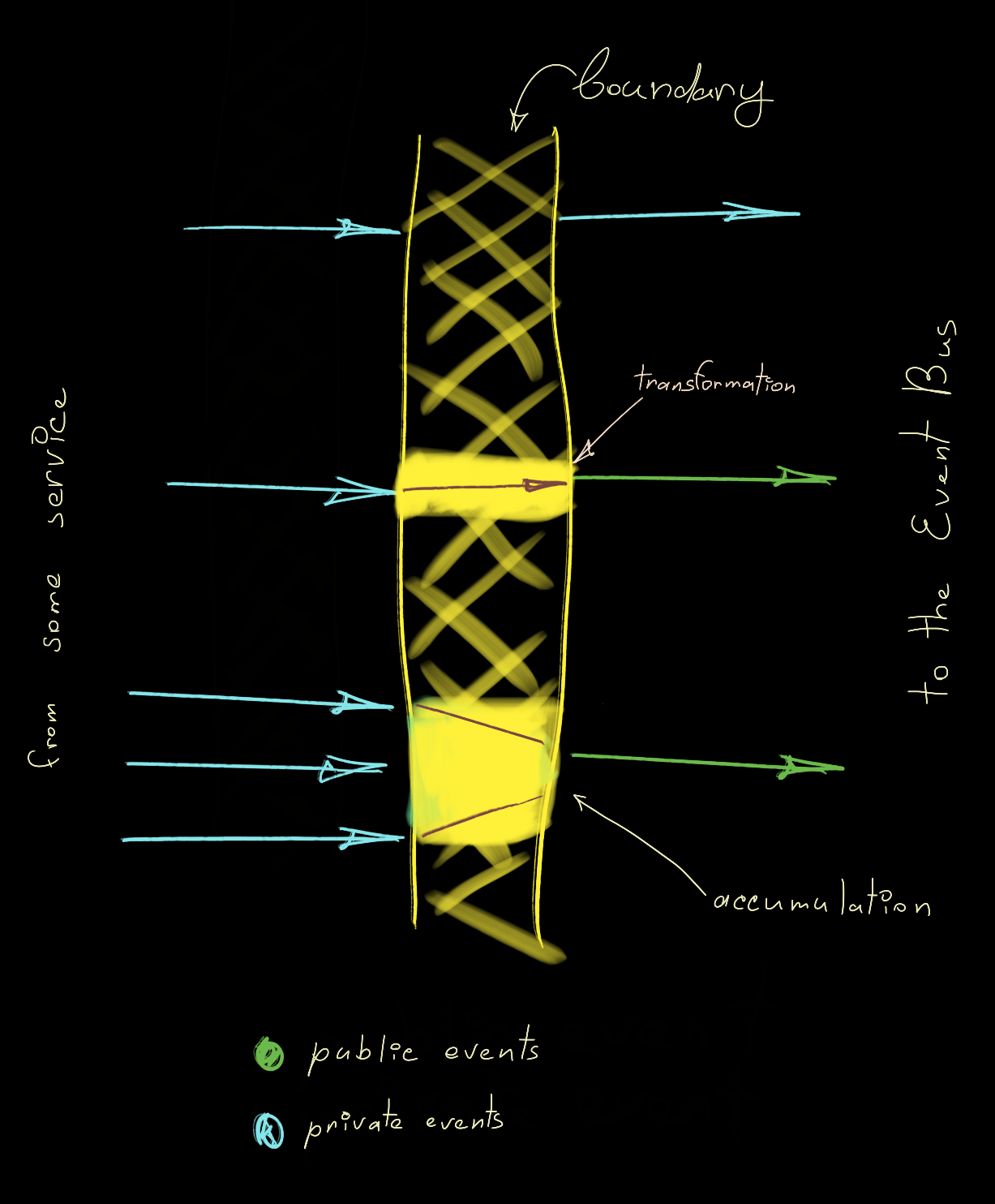
This is where the terms private event and public event are coming from. Private events are emitted and consumed inside our system/application/domain, where we have full control over the execution environment. Whereas our public events live outside and are caused by private events. We might or might not have control over consuming services outside. Sometimes private and public events also differ in carried payload, therefore slight transformation might be required just before emission outside.
Accumulation
Nevertheless, sometimes it is not enough just to have private events causing public events. If we want to keep our private events granular and each or some private events will cause public events, that would make a lot of unnecessary noise outside. Moreover, it won’t give much value to downstream services. As they are probably not interested in every change that occurs in our service.
This is where the accumulation strategy comes into play. Event accumulation is a process of gradual data accumulation from series of private events to build a single public event. Once the “trigger” private event happens, the public event is released and emitted and accumulation might start all over again.
Accumulation functionality might sit right on the boundary between the service and the outside. You might know it as an adapter pattern from the Hexagonal Architecture.
P.S.
Sometimes the term Event-driven architecture is used exclusively for describing asynchronous services communication. However, I like to use this term to describe the family of approaches, technics, and patterns that engage events in one way or another.
We ran through some of the Event-driven architecture representatives. I’ve tried to keep myself as close as possible to the original article line. However, I had to slightly touch base on some conjoint topics. Although I had to limit myself, otherwise I would never finish this article.
That said more to come, so stay tuned.